14 - Syntactic Parsing
ucla | CS 162 | 2024-03-11 02:55
Table of Contents
Syntactic Parsing
- syntax is the characteristics of words and interdependent relations that help w interpretation
- we parse as a tree from sentence (bottom) up
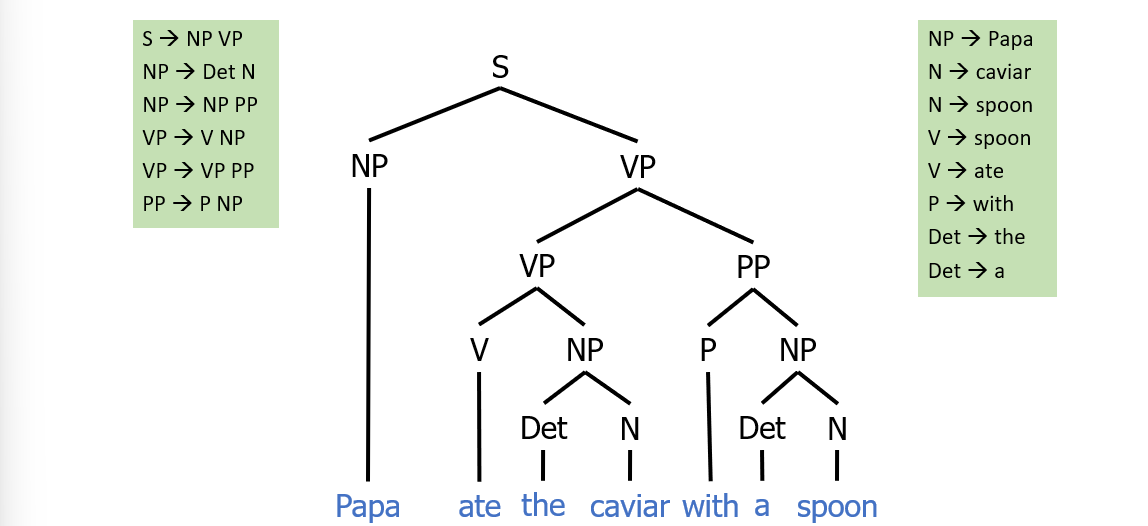
- nonterminal rules: a rule that decomposes to other rules:
- terminal rules: rules that decompose to a word/token:
- natural language has lots of overloading/ambiguity and grammar isn’t known in advance
- evaluation also requires true parsed outputs
Evaluation
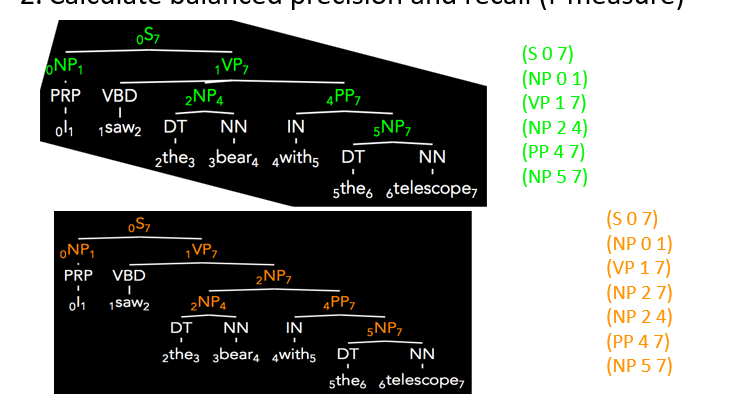
- decompose true to labeled constituents (only given rules, POS tags not considered - but usually labeled regardless)
- calculate balanced precision and recall (f-measure)
- green is predicted, orange is true (predicted as a tuple of the nonterminal and (continuous) span of the nonterminal rule):
F1, Precision, Recall - PROCESS


Parsing
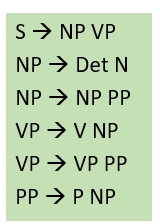
Grammar Rules
- the set of nonterminal and terminal rules given by natural language
- also the span of each token

Process
 the next pass, we look over all constituents of all previous passes and check if any start with the end of any current constituent
the next pass, we look over all constituents of all previous passes and check if any start with the end of any current constituent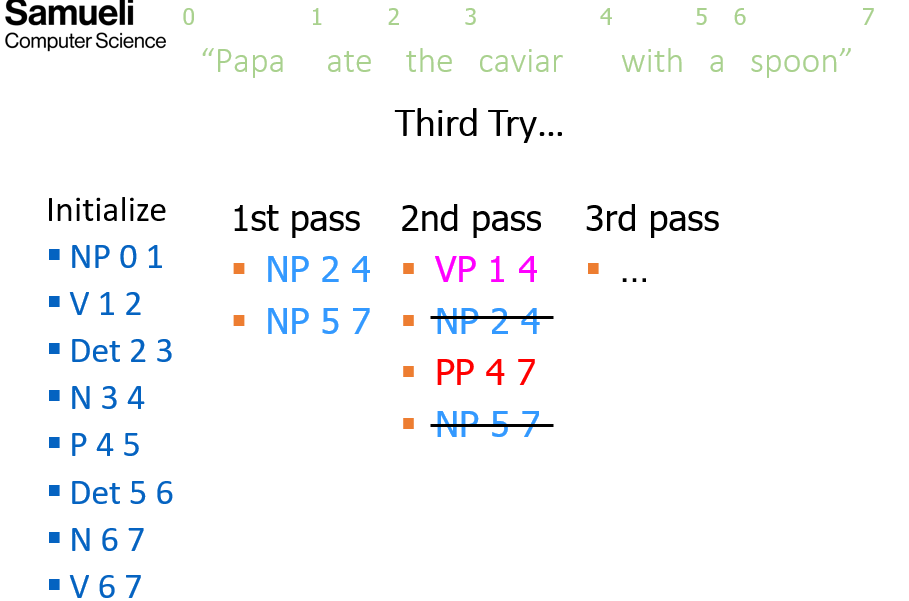
- complete/optimal but inefficient
Optimization
- tabulate in a chart of the sentence span
- original algo:
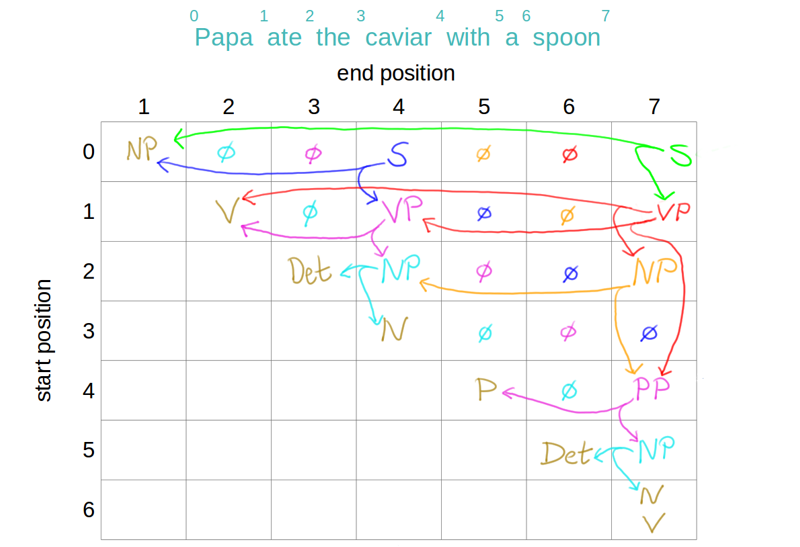
- iterative deepening of width, build with width-1, then width-2, (done by iterating over diagonals, remember constituent spans must be continuous) etc.
- width-1 is diagonal
- width-2:

- width-4:

- to find a width-N constituent given all lower N constituents, we consider the possible N length spans and check which follow a grammar rule:


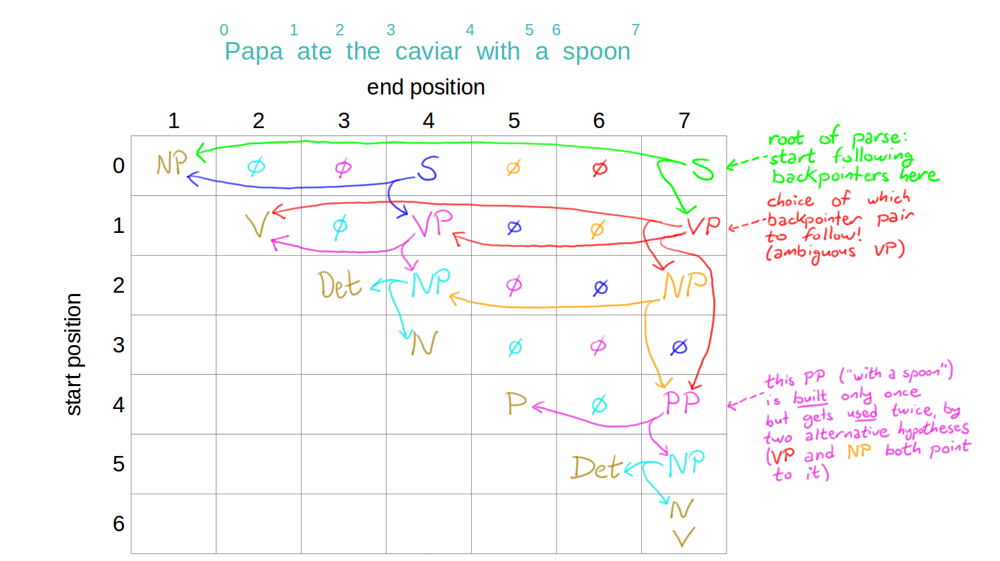
CKY Algo (Recognizer)
- an algo to check if a sentence is parseable i.e., if a parse tree exists for the sentence

- given the grammar rules, the tabular representation of spans, and the sentence, we determine constituents of length N as diagonals of the table:
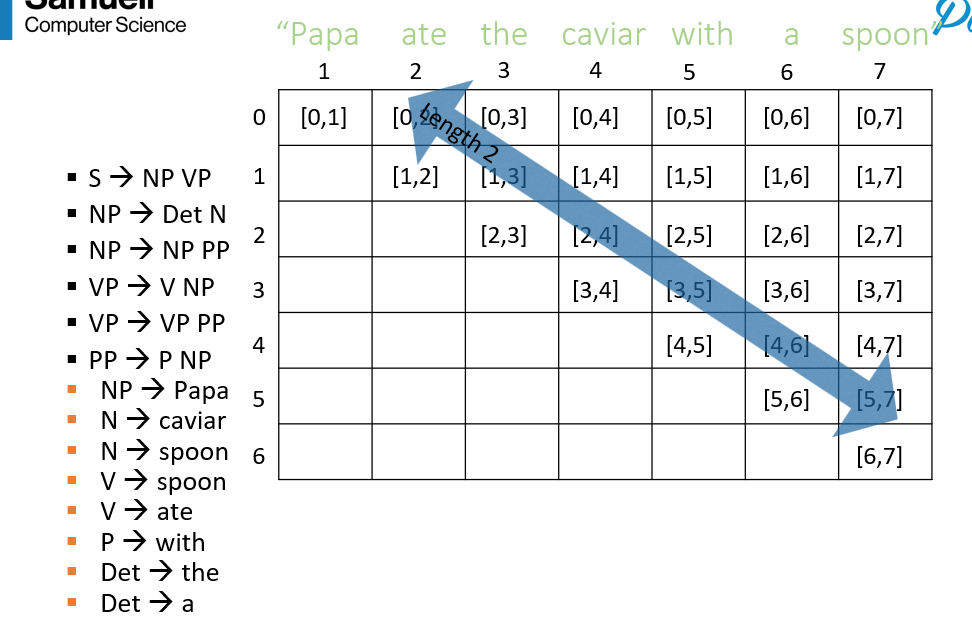
- Psuedocode:

Analysis of Algo
- reasonably efficient (poly)
- requires Chomsky Normal Form (nonterminal and terminal rules of 1 level order only, i.e., what we have above)
- this CKY can check grammar
- but also generate entire forest with all ambiguity
- we can analyze ambiguity by counting trees in forest generated
CKY Parser (Probabilistic)
- to mitigate ambiguity (due to same POS) like so:

- many possible parses but some much more probable than others
- assign a weight to each rule, select lowest weight (NOTE we use neg. log-prob so lowest is highest prob) s.t. tree’s weight is total weight of all its rules
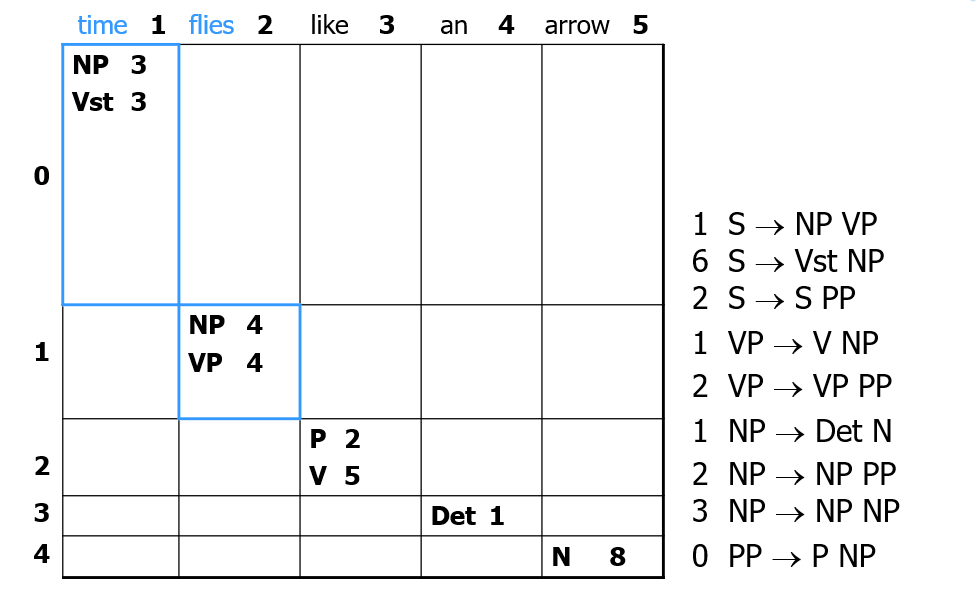
Process
- initialize w/ width-1 along diagonal, grammar rules with weights (We want lowest), and sentence with spans:
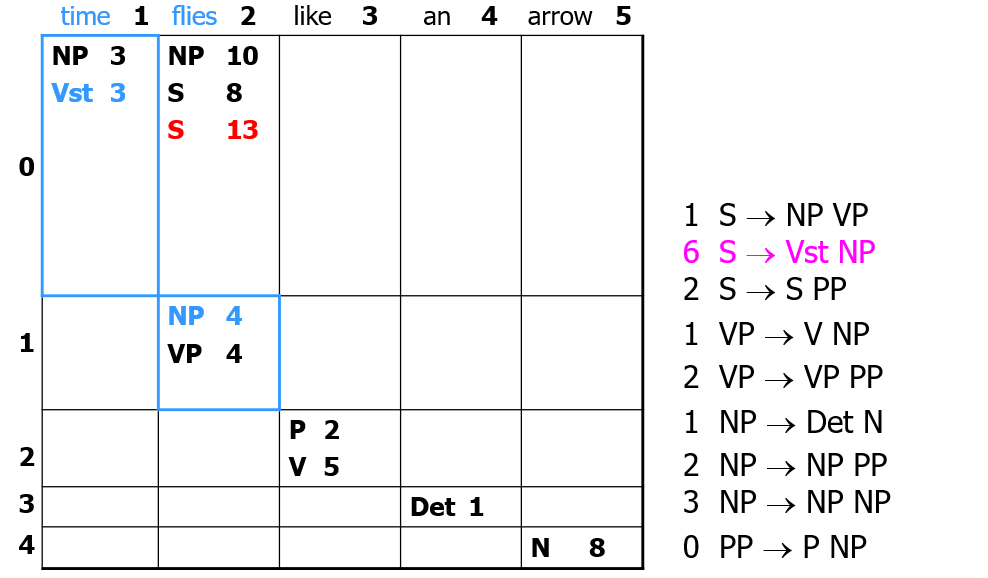
- then run IDS and when ambiguity occurs, select lowest weight rule that works for that N-length constituent
- the weight of each constituent is the sub-constituent weights plus the rule weight (red from blue and purple):
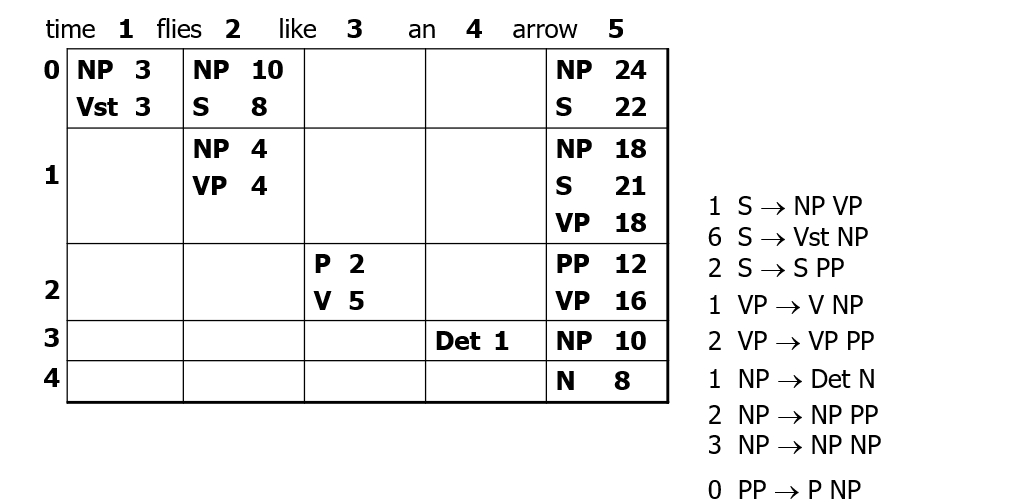
- then, from root, follow backpointers of lowest weight:
- cull the inferior constituents that we dont need in each span:
Variations
- keep track of total probs of all possible parses of a sentence (Inside algo)
- track all possible parses and their probs
Training
- count and divide
- featurized training
Penn Treebank
- databse of grammar rules that we use as terminal and nonterminal rules for our parsers
- eval f1 score on trees
- train using span splits
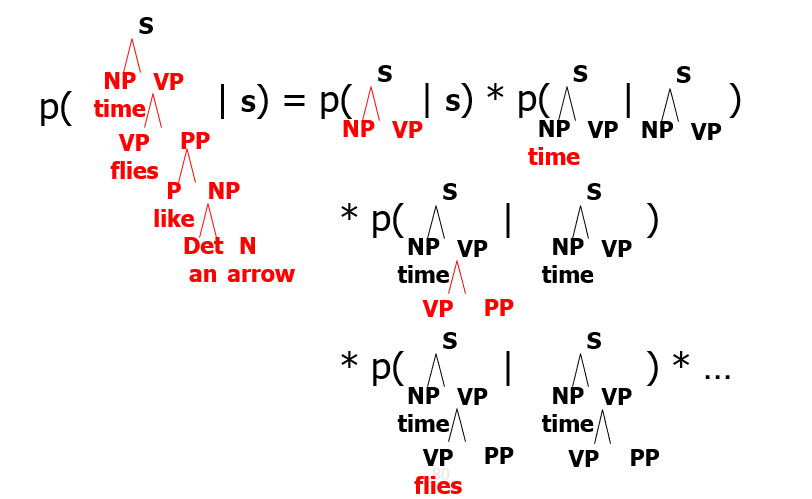
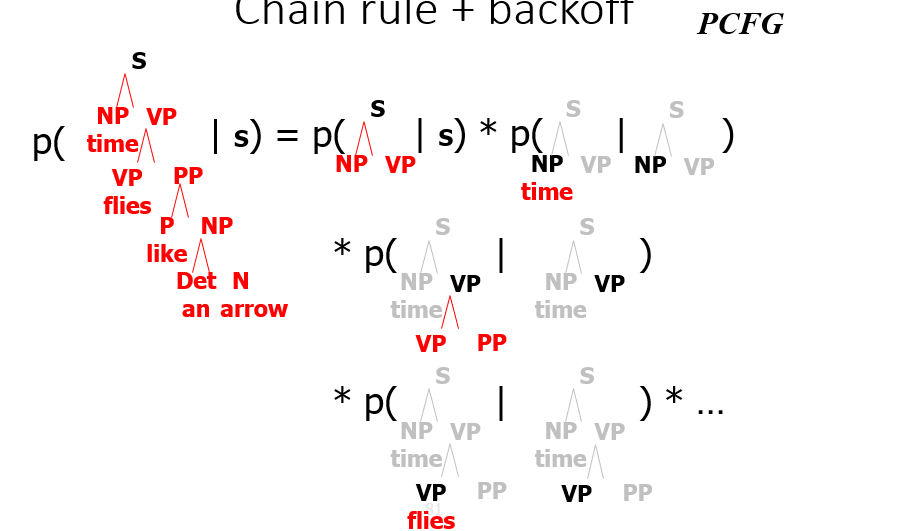
Count and Divide CKY Probs
- the true probability of the tree given the sentence, we use the probability chain rule:
- but to estimate, we make the independence assumption that subtrees are independent of other subtrees given their immediate parent and apply backoff



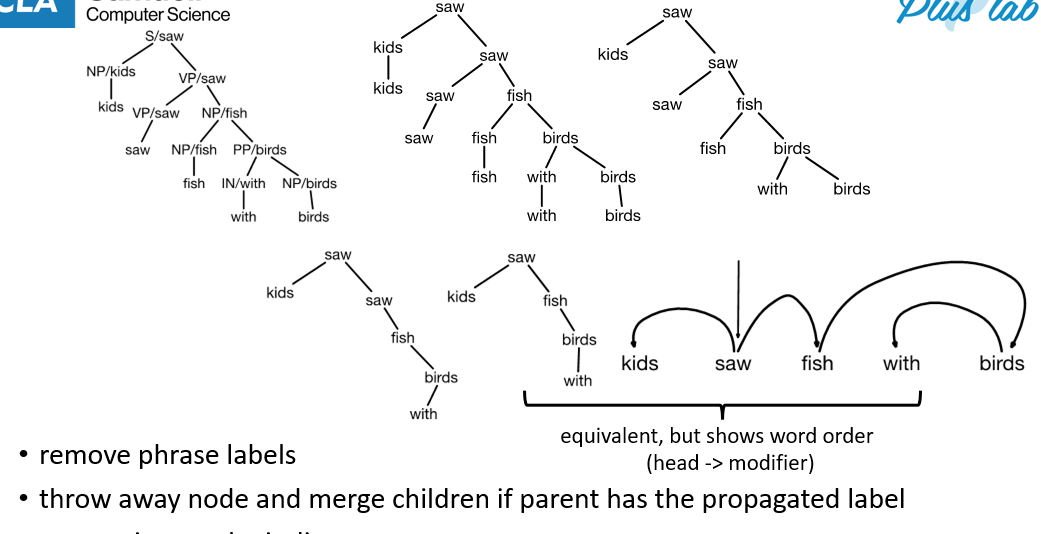
Dependency Parsing
- constituent view of syntax (CKY) does not consider discontinuous information or POS tags
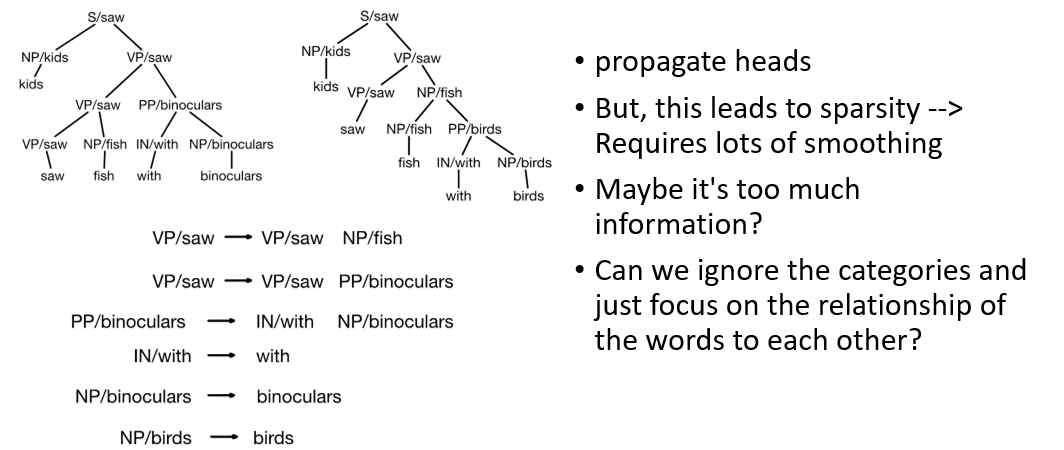
- constituent view als oloses lexically grounded selection preference, we instead may need to create many rules (propagating heads) depending on how the sentence should be interpreted
- this can introduce too much information downstream making probs low and hard to learn
- instead we can remove lexical tags and redundant term to derive dependency tree in-line
Dependency View of Syntax
- no explicit phrase structure
- features how words relate to each other instead of syntactic phrase only
- closer alignment bw analysis of structure of diff langs
- natural modeling of discontinuous words
- lexically grounded relationships
- loss of expressivity (cant go back to constituency tree from dependency)
- requires definition of head
- may be good to assign labeled edges in dependency tree
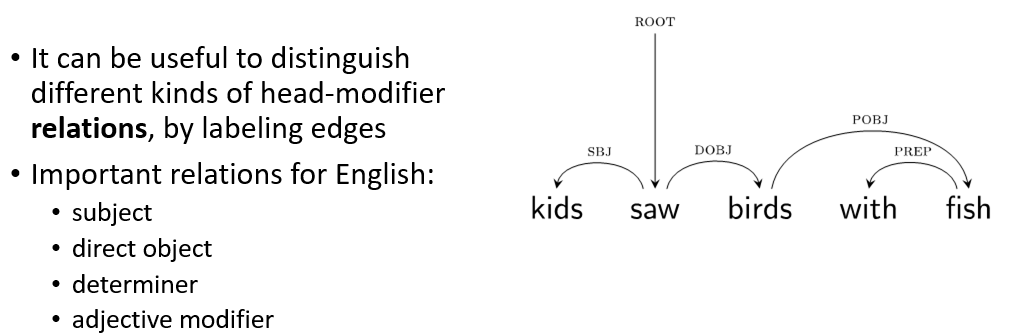
- similar to PTB, other treebanks made for depenndency trees: Prague, Universal
- issue is determining head to start with, so we split into functional and content heads and usually start with content heads as root
Projectivity
- a dependency tree is projective if every subtree occupies contiguous span and does not cross other subtrees
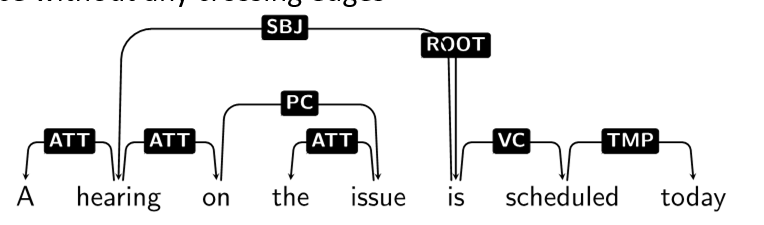
- non-projective is not as common in english lang
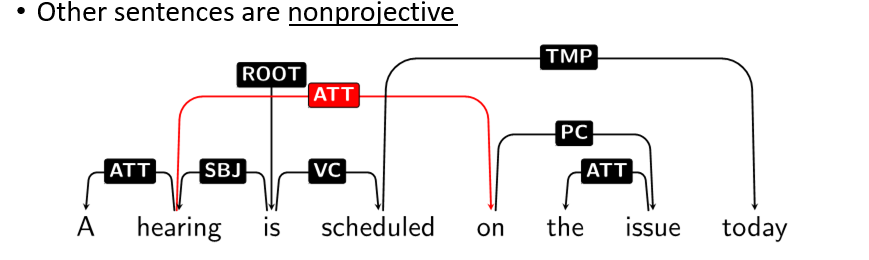
Parsing Approaches
- constituency and project
- build CKY parser then project down to dependency
- but does not handle non-projective situations
- graph based
- Chiu-Liu Edmonds
- find MST of the possible graphs of the sentence
- quadratic time
- transition based
- keep a stack of words and work at the top of the stack
- have 3 ops
- e.g., given the ground truth tree (we know we want to root at book)
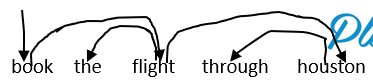
- we end up with this parsing procedure
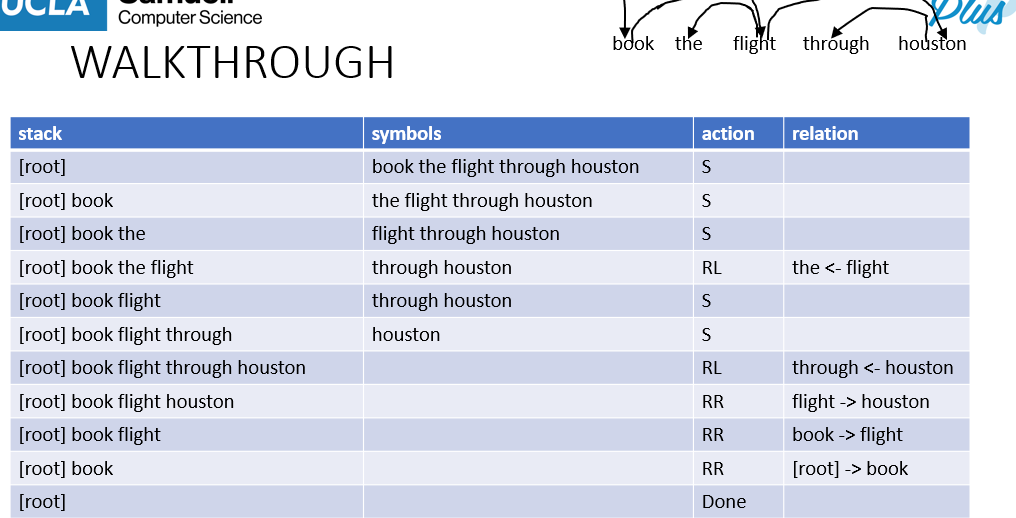
- we only reduce-right (RR) AFTER all subtrees of the possible child word have been linked (i.e. all RL for the word have been done)

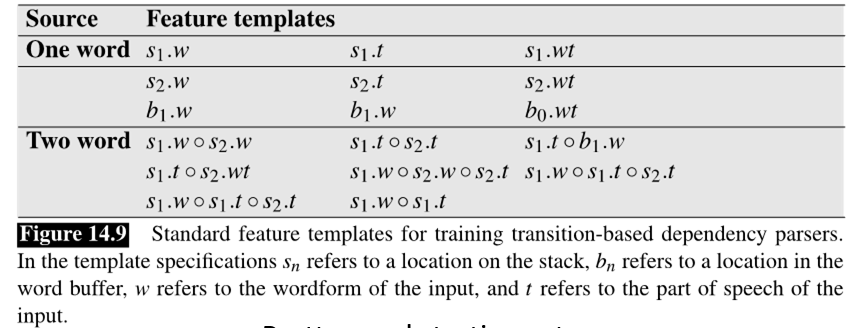
Training
- Input is sentence -> output is decision of OP (S,RR,RL), using a deterministic algo

- Thus, we train probs
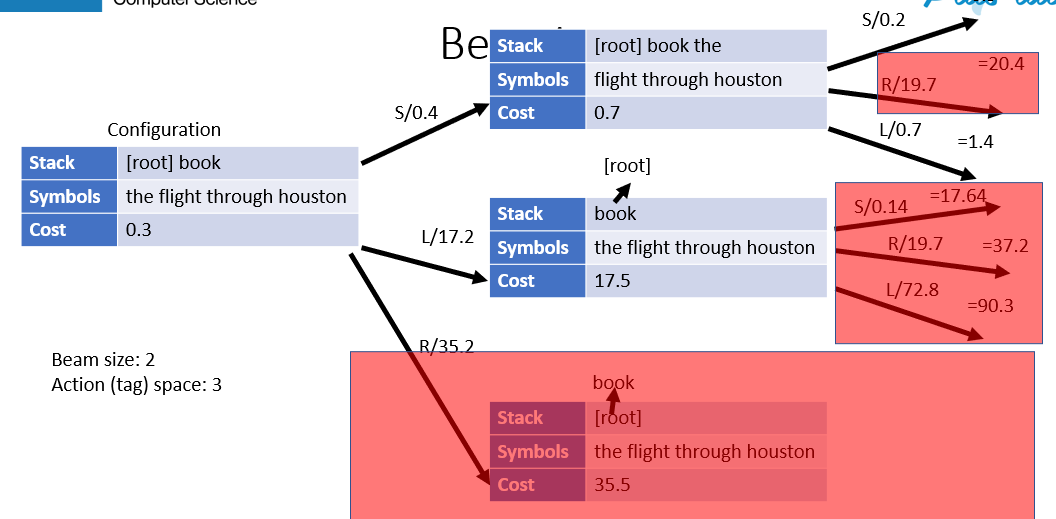
Beam Decoding to prevent bad Greedy
- choose top k (Accumulating cost) at each step