8 - RNN and LSTM
ucla | CS 162 | 2024-02-06 13:16
Table of Contents
RNNs
- use sequential information to make preds
- don’t make independence assumption (unmlike FFNNs)
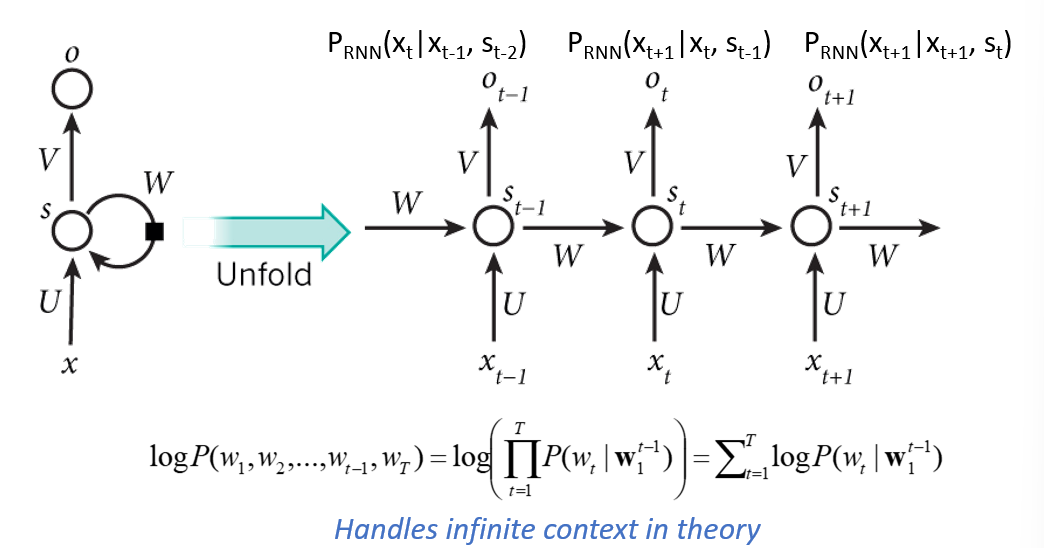
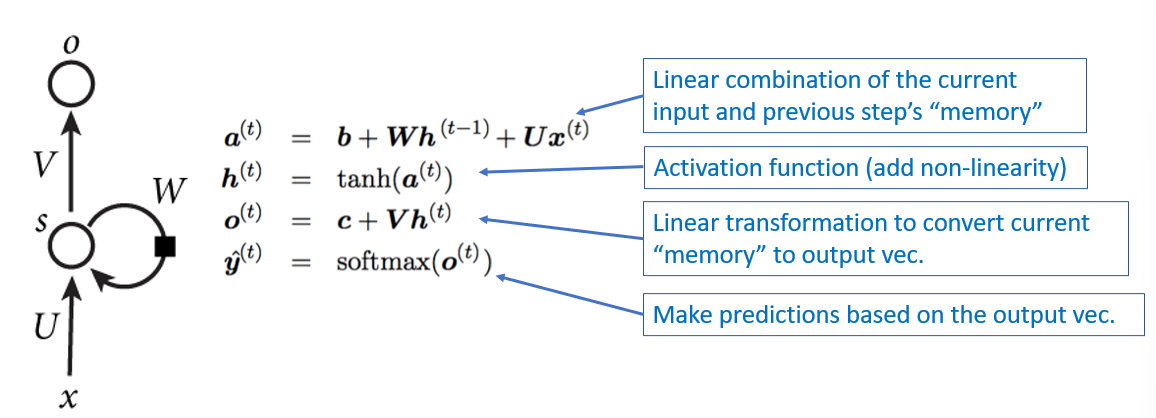
- perform same task at each step of a seq and inputs of next step req prev step outputs -> memory
- this is better than n-gram because we can generate probs conditioned on the WHOLE context
Long-Term Dependency Limitation
- RNNs are theoretically capable of handling long term memory that generates outputs that are dependent on tokens much much earlier in a long context
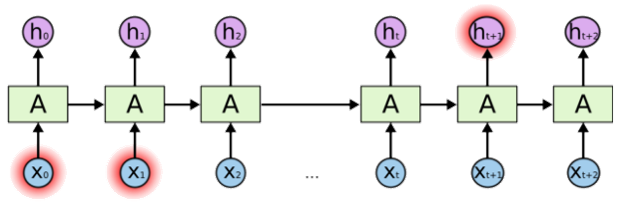
- but irl they are not do to vanishing gradients of context from very far back in the context
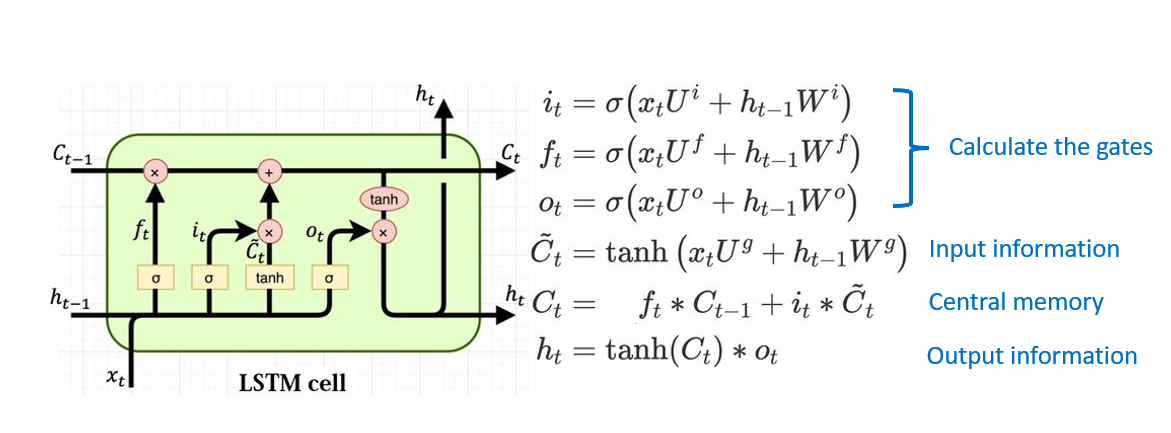
LSTMs
- designed to mitigate long-term dependency issue w/ RNNs
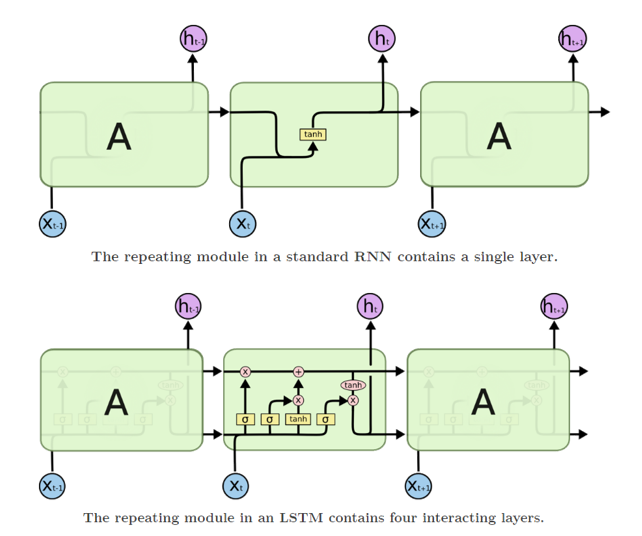
- the key is memory cell state that add or remove info as seq progresses by changing cascading multiplications to additions of probs
- this is done using 3 gates to control memory (input, forget, and NS/FS)
- NOTE: different weights across each gate (look at subscript)
Input Gate
- decides what info from current input to capture in cell state
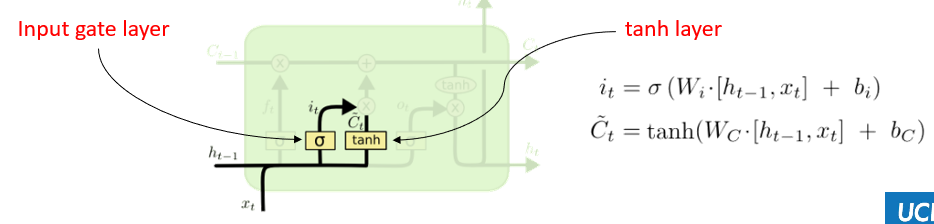
- consists of 2 parts
- sigmoid (input gate layer) - decides what values to update b/w/ 0 to 1
- tanh - creates a vector of new candidate values (contextualized seqs)
- e.g., adding gender context of new subject to cell state and replace old context
Forget Gate
- decides what info to remove through sigmoid layer
- looks at prev hidden state
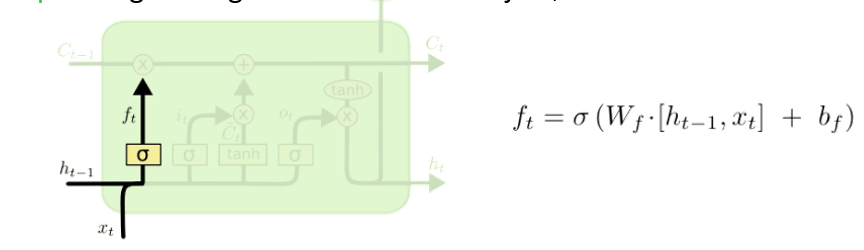
- e.g., forget gender of old subject when we see new subject
Next Step Context (Cell State)
- update old state
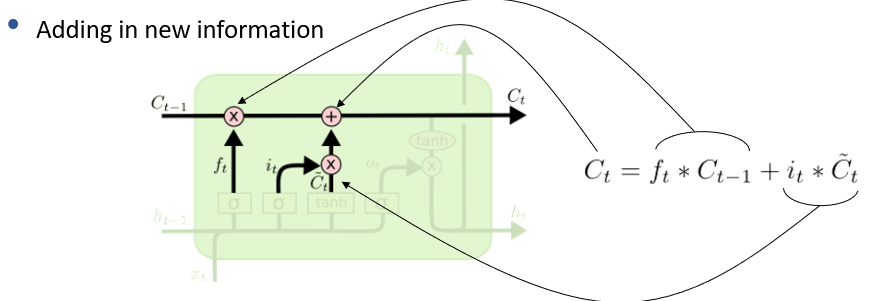
- multiply old state by the forget gate
- add in input gate
Output Gate
- decide outputs by computing output gate then multiply into cell state to get outputs and propagate to next cell
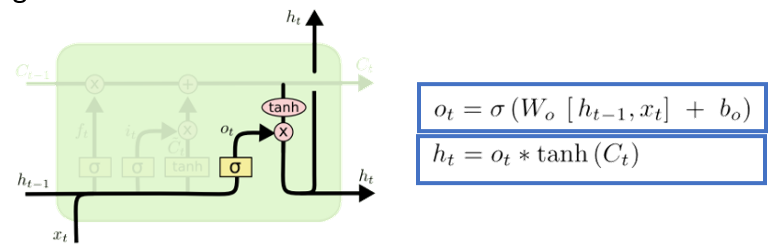
Complete Structure
- add bias to each of the below params
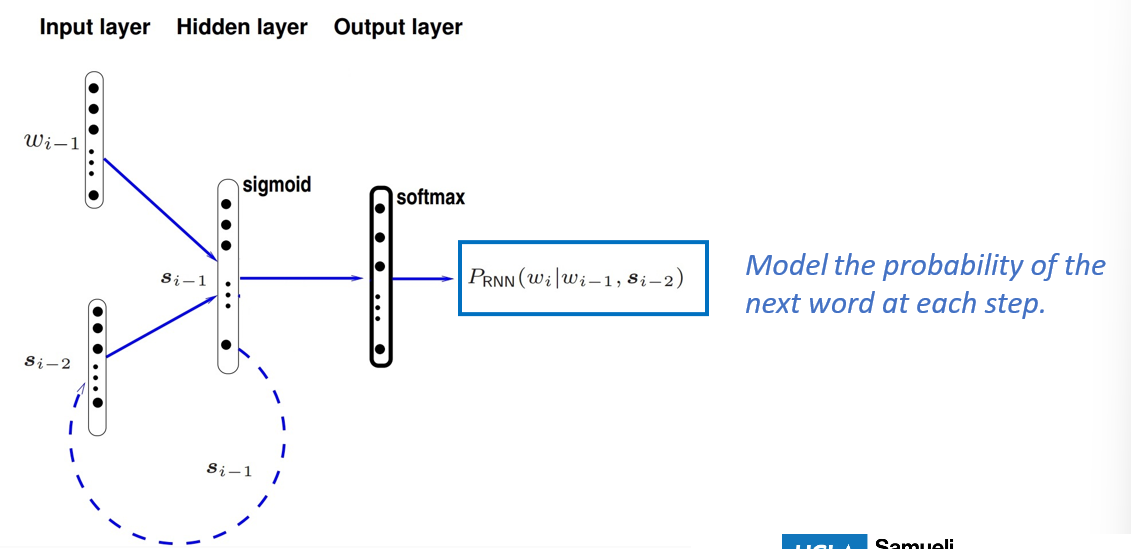
Learning Neural LMs (Recap)
