11 - SuperScalar Procs and RAT
ucla | CS M151B | 2024-02-15 16:10
Table of Contents
CPU Performance
- latency - time to complete a task
- throughput - number of tasks per given time
- effectively reduce CPI to 1 per instruction but CT increases due to propagation delay
Multi-cycle effect
- decrease CT using latches between stages by 1/num_sstages
- but increase CPI
Pipeline effect
- smaller CT and CPI
- but requires more hardware and cost and control hazards
- adding more stages increases CPI while benefits to CT reduction are limited
- requires more forwarding and control hazards
Reducing CPI
- increase instruction throughput IPC=1/CPI
- parallelize with
- e.g., extend scalar pipeline to IPC=2 by grabbing 2 instruction simultaneously; then we must change the behavior of the stages
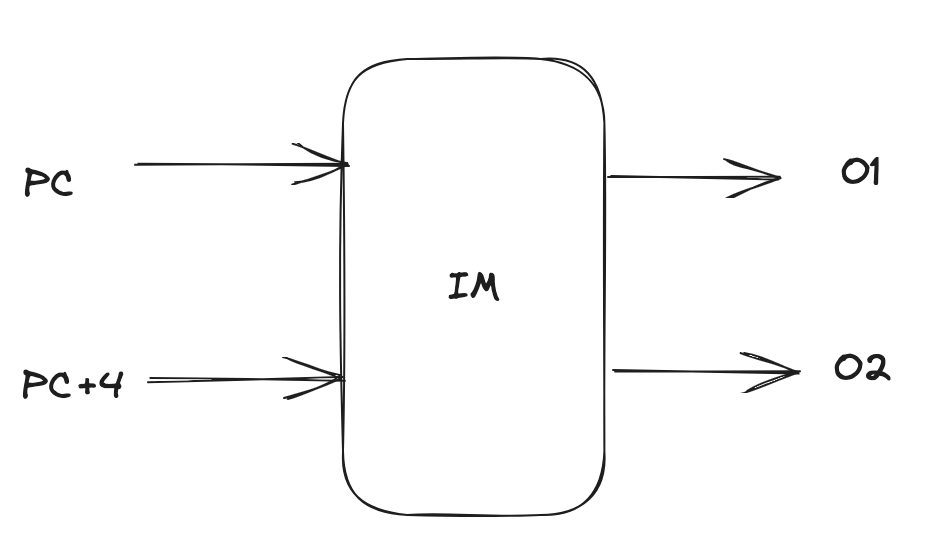
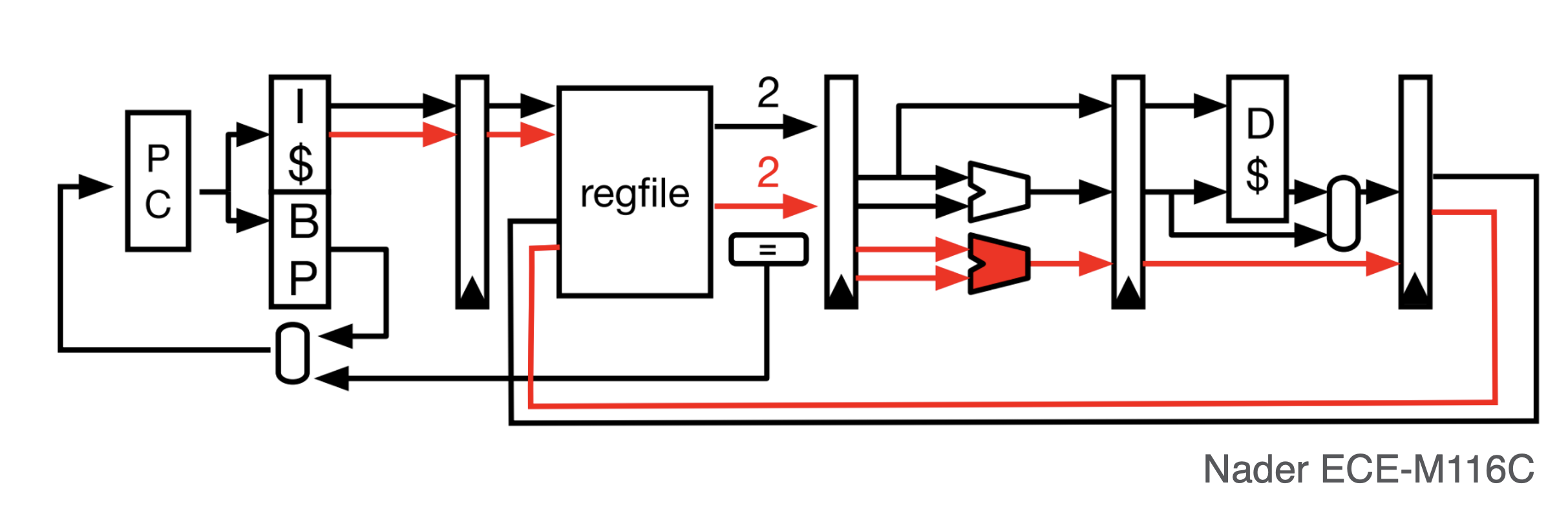
IF stage
- still just 1 PC, but we increment by 8 bytes for each cycle
- BUT, we change IM (instruction memory) to accept 2 inputs (PC & PC+4) and create 2 outputs:
- i.e. multiple read ports
ID stage
- replicate decode hardware
- have multiple read ports to register file
EX stage
- replicate ALU (2 ALUs)
- or to decrease cost, we make each ALU partition the set of possible ops
- will also require
- e.g., ALU1 does arithmetic and ALU2 does logic; but then must ensure that either stalls if Instruction 2 does not require the ALU or only requires one of the 2
MEM stage
- no replication, just have 1 ALU output that goes to DM
- if the other ALU output ALSO needs to access memory, we stall for 1 cycle and redirect the 2nd output to the DM as well
- this can happen but is much faster and much cheaper than replicating DM for when both instructions don’t need to access DM
WB stage
- have multiple write ports to the register file
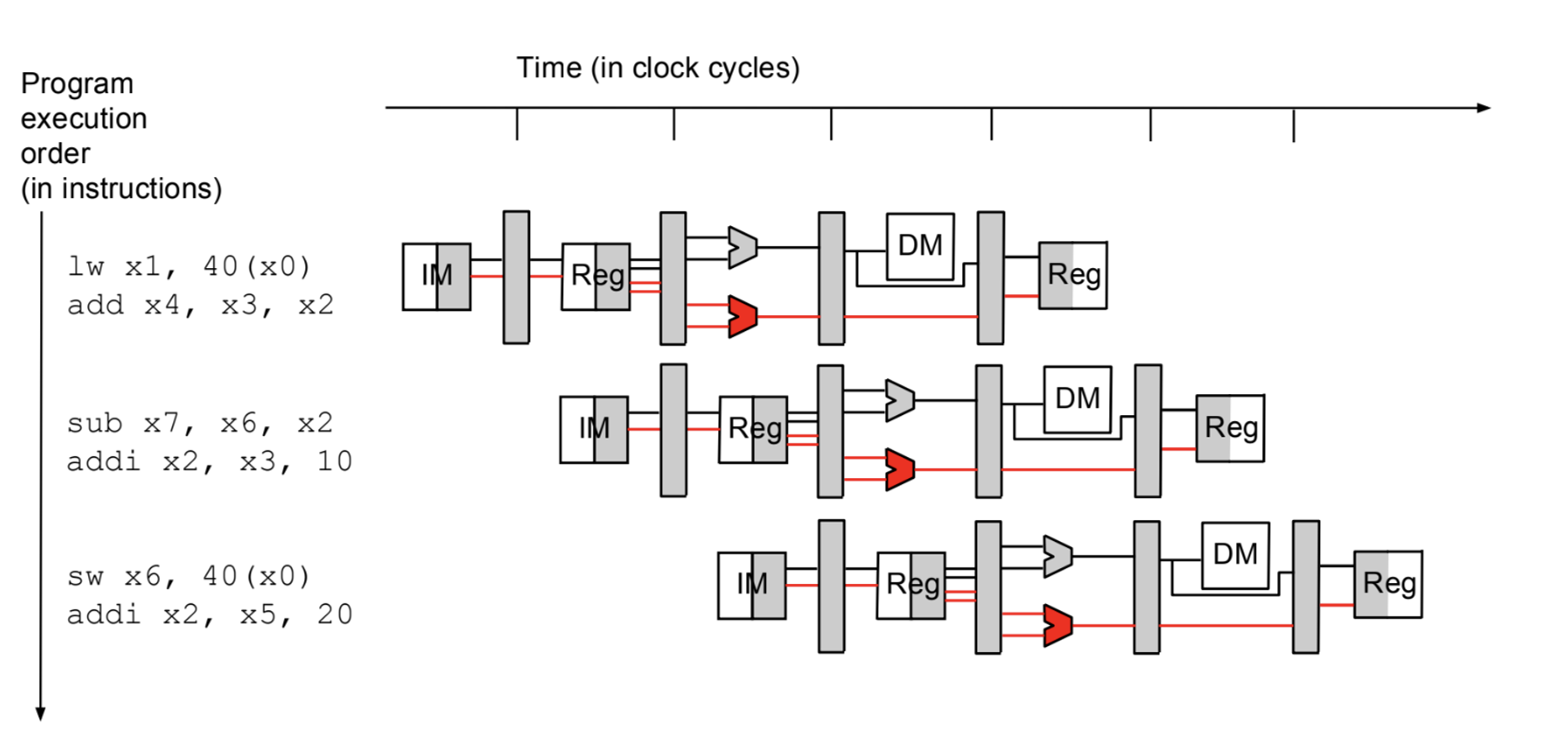
Control Hazards and Data Forwarding
WAW

- Write after write is an issue now and ordering of write must be enforced
- we can do this by delaying the bottom wire
RAW
- RAW is much more of an issue now depending on the IPC inrease, e.g. if we read 4 instr in parallel (N=4):

- so most super scalar stop at 4 parallel instrs bc checking is very expensive wrt to N
Tradeoff
- higher IPC
- but higher hardware cost: replication, dependency checks
- also stalls can affect IPC
- but we can mitigate stalls by performing parallel instructions out of order
- the isssue is resolving intsstrution dependency so parallel instruction handling rarely ever reaches all N scalar procs in a superscalar, isntead we an try OOO
Out of Order Exec (OOE)
To eliminate WAR and WAW dependency
- go through instructions linearly, if we observe a group of parallelized N instructions that are not independent, we skip one of them and choose the next one (each time we execute an instruction it is “Removed from our list”)
- problems: finding available instrs, tracking dependencies, pipeline hazards, memory preservation
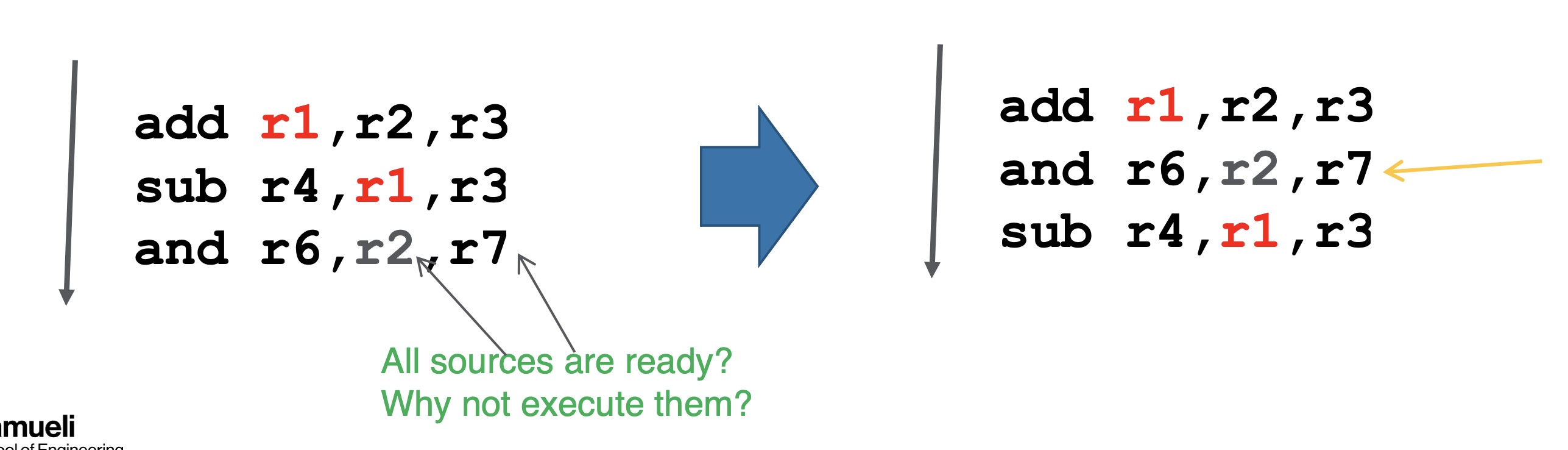
Static Scheduling
- compiler internally track dependencies
- have compiler be clever and reorder instructions when it observes instructions are independent
Dynamic scheduling
- now we observe that having many more registers can help mitigate dependency but register file reimplementation cost is too high and we don’t want to change ISA
- instead we use internal registers called “physical registers” (more free regs than ARF)
- and call ISA regs “logical or architected registers”
- and we map logical regs to physical regs
- then we need a mapping algo and physcial registers (to allocate/deallocate)
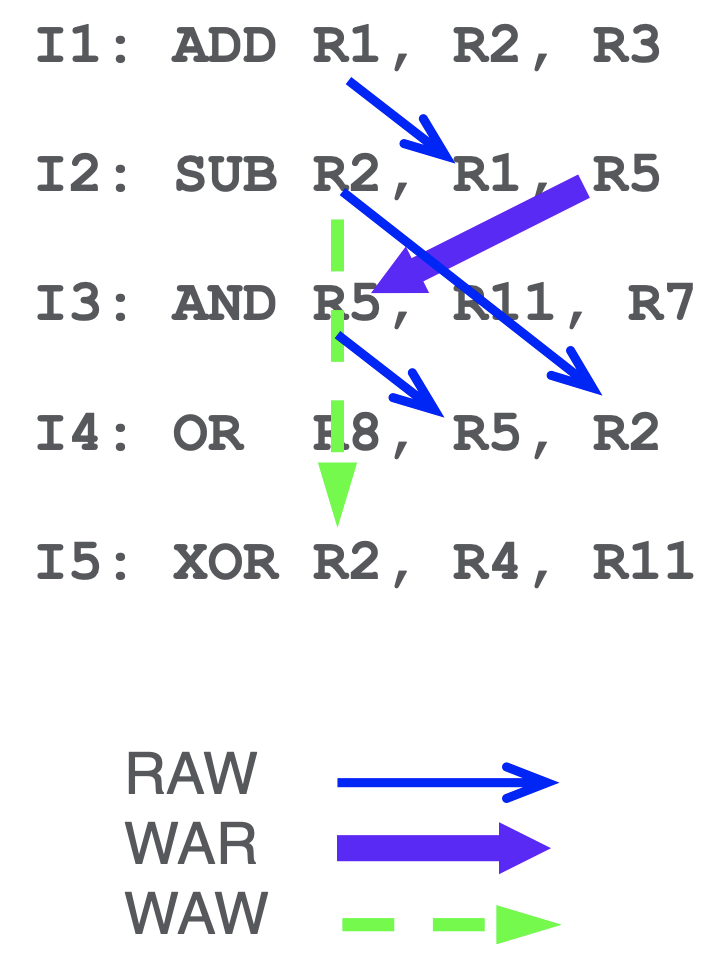
- the following example is mising 2 WAR: b/w I1->I2 and I4->I5, but assume they are not there:
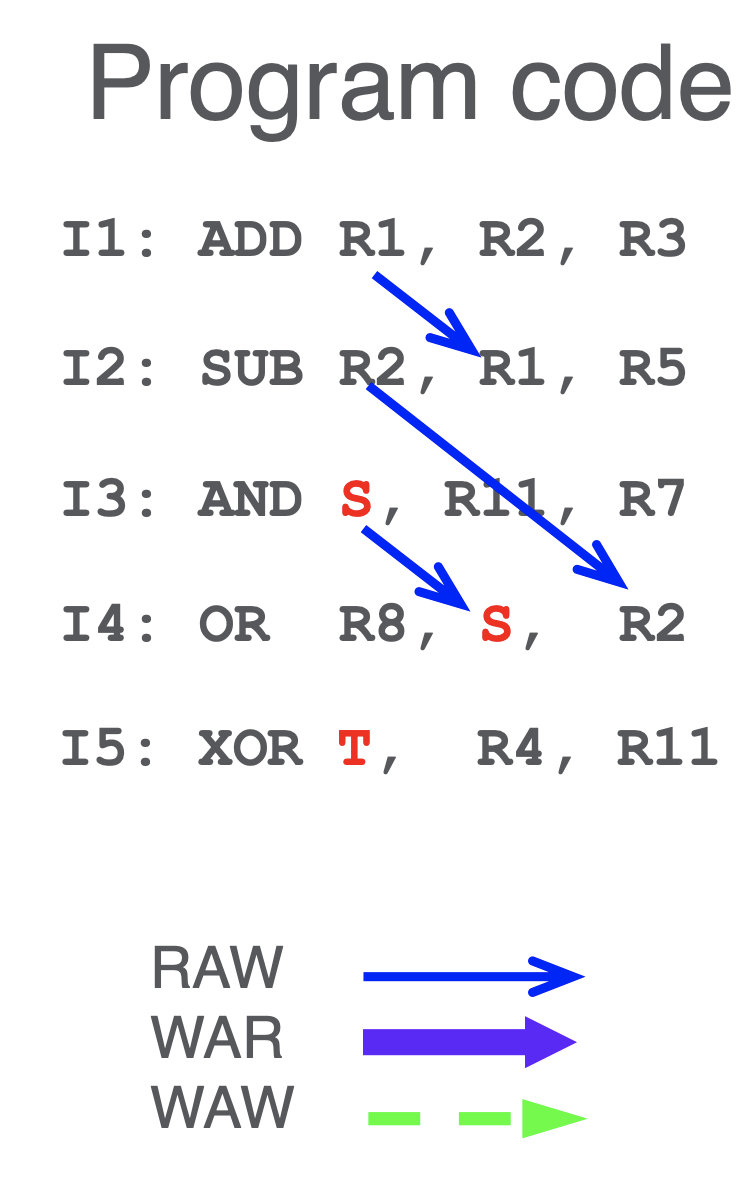
- then we can decouple I2 and I3 by mapping R5=S in I3 and propagate downward - this removes a WAR dependency
- do this for WAW as well by mapping to T
- for each instr, everytime we write to a reg, rename it
- then keep track of renamings and reqrite any decodings of it in future instructions
Physical structure
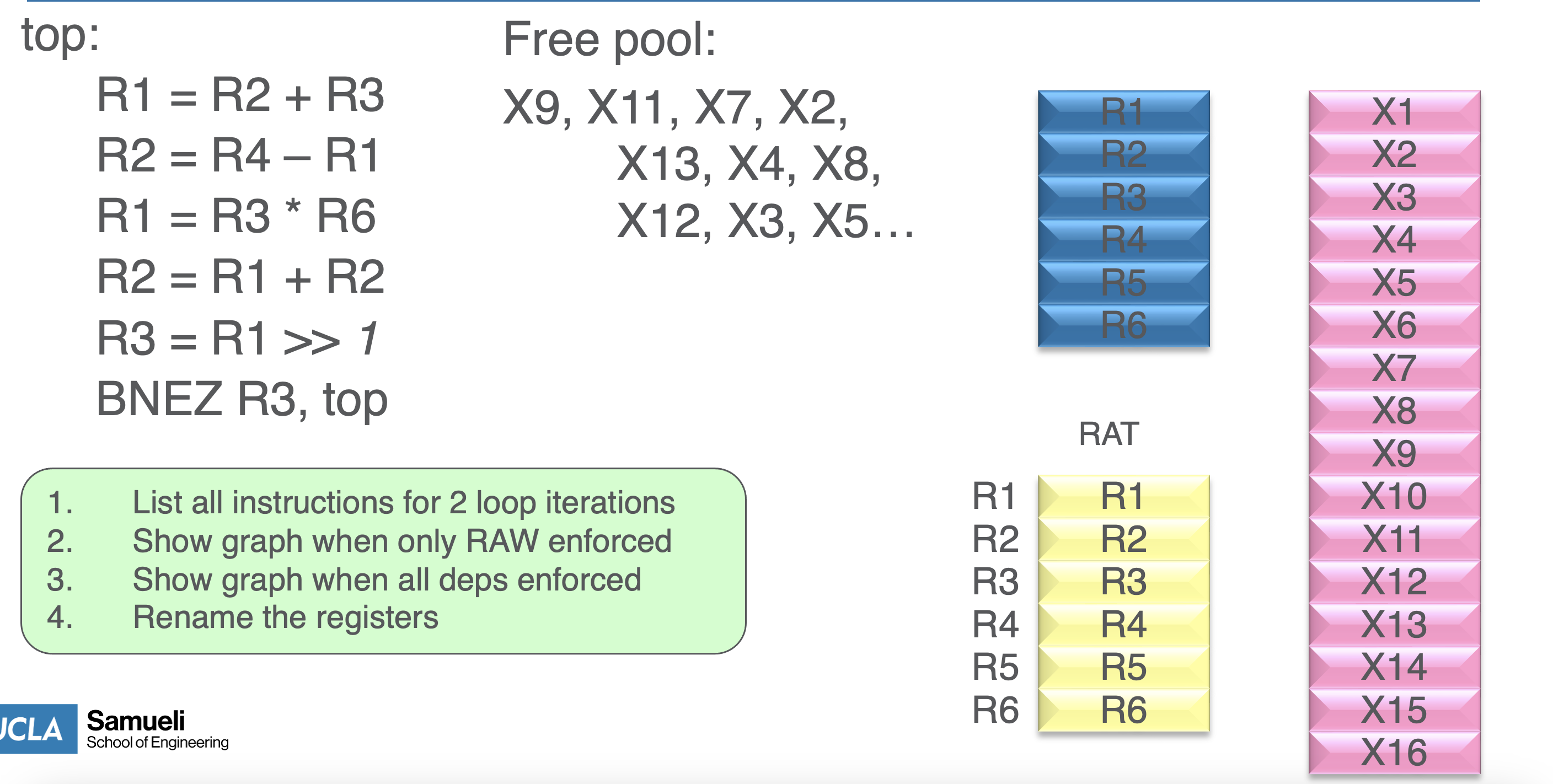
- we do this using a RAT (register alias table) that maps to ARF and PRF (an abstraction)
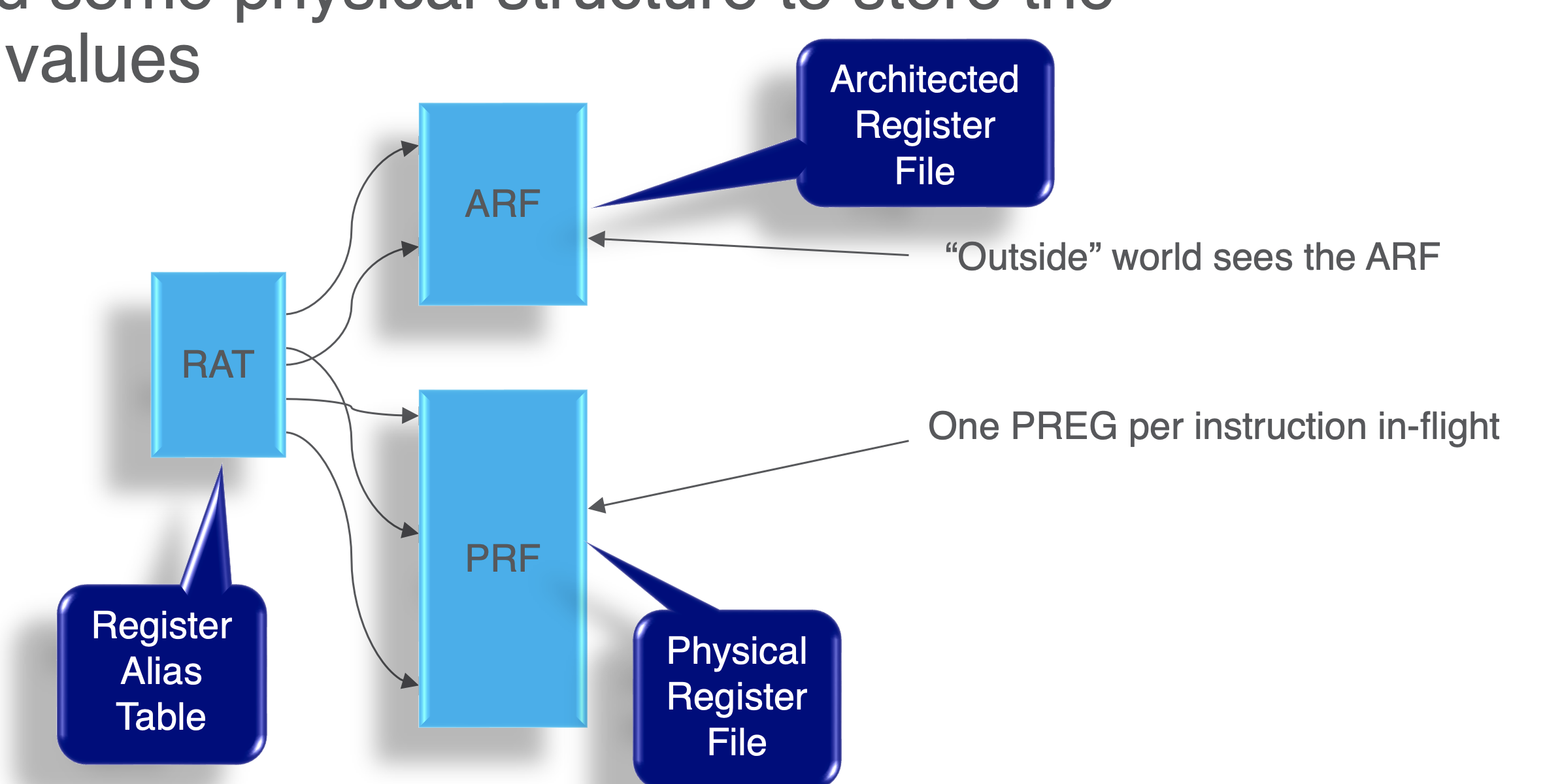
Process
- setup
- dependency observation
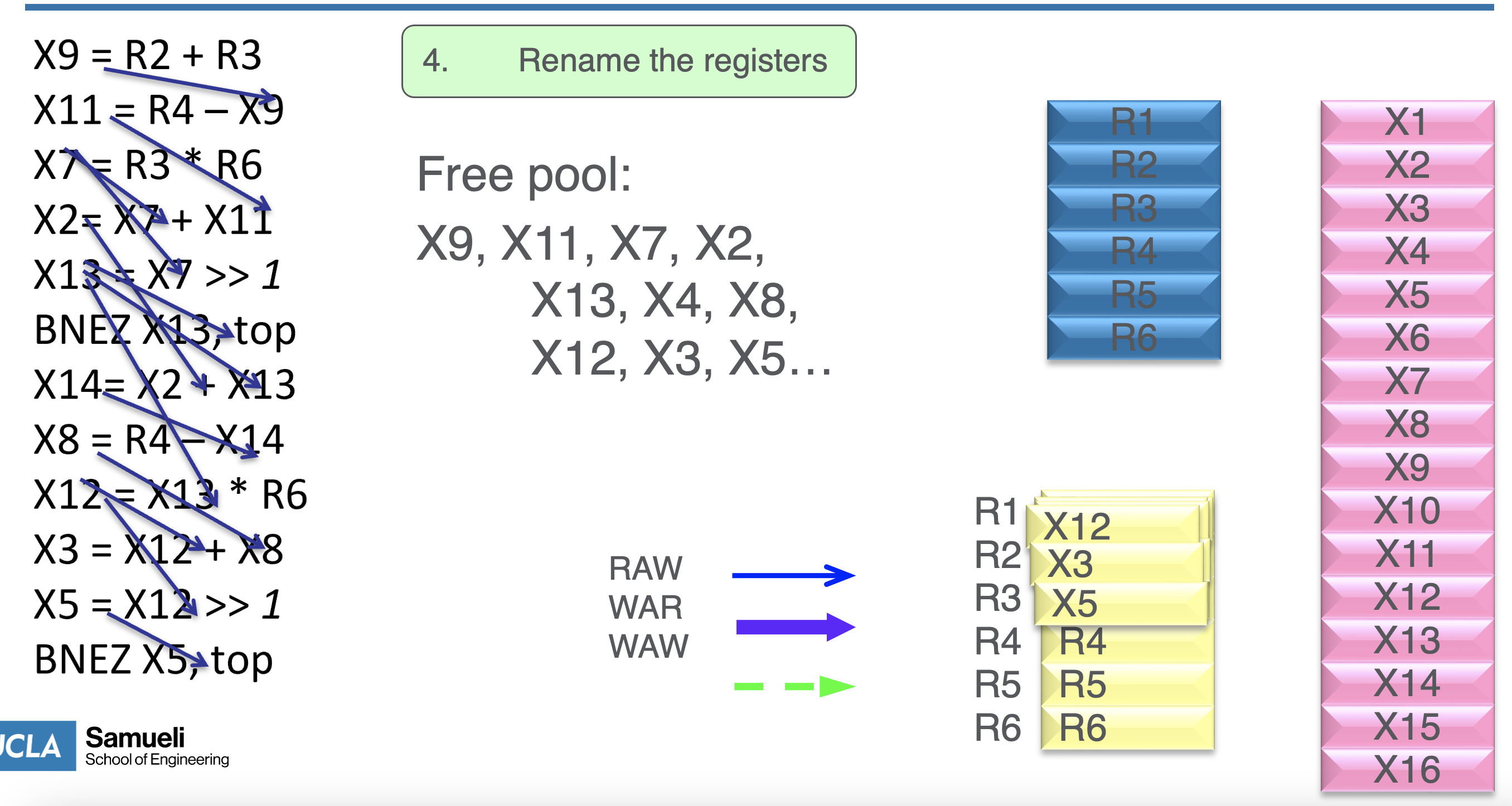
- rename dest regs and propagate
- repeat until program ends; if physical regs are full, stall until they are freed
- during operations, recycle physical regs after the last instruction in the program requires it - we can know when to do this by when the renamed register is once again used as a destination reg
- once this happens, we can reflect this change to the ARF to make the operations “true/visible”