13 - ROB
ucla | CS M151B | 2024-02-22 16:08
Table of Contents
Modern processor pipeline so far
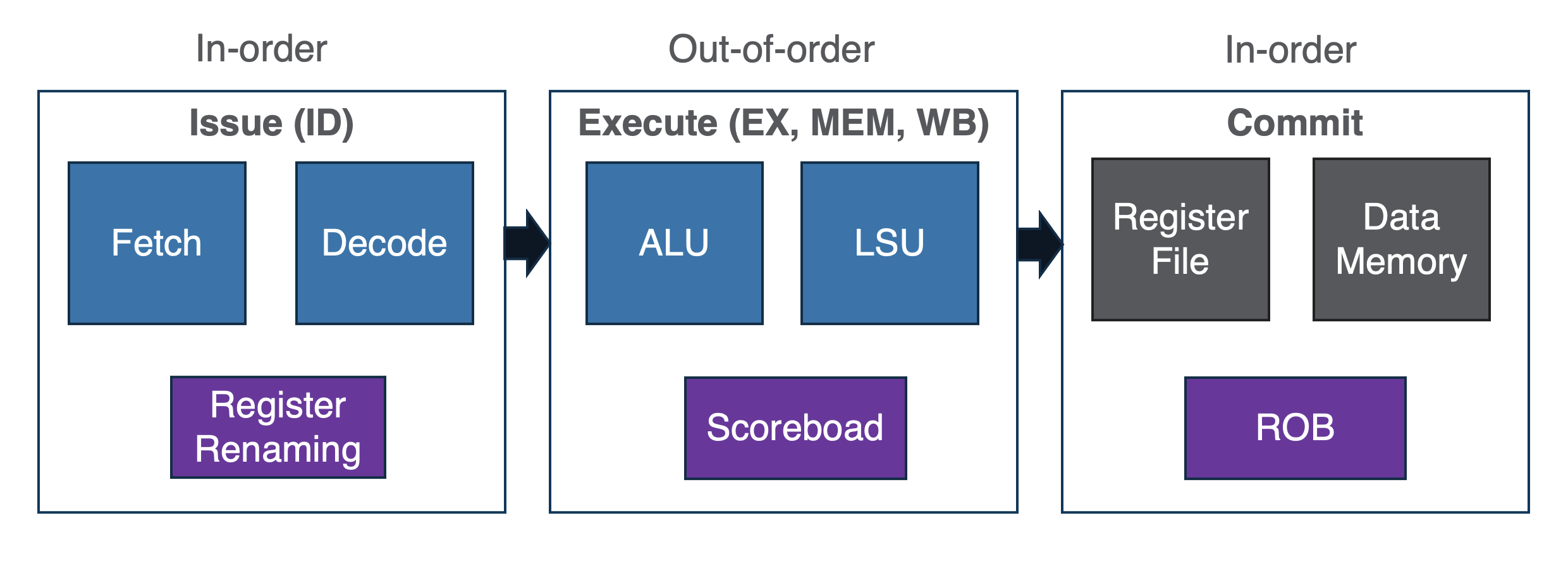
- introduce register renaming to mitigate data dependency
- introduce scoreboard to mitigate RAW hazards
Dynamic Scheduling
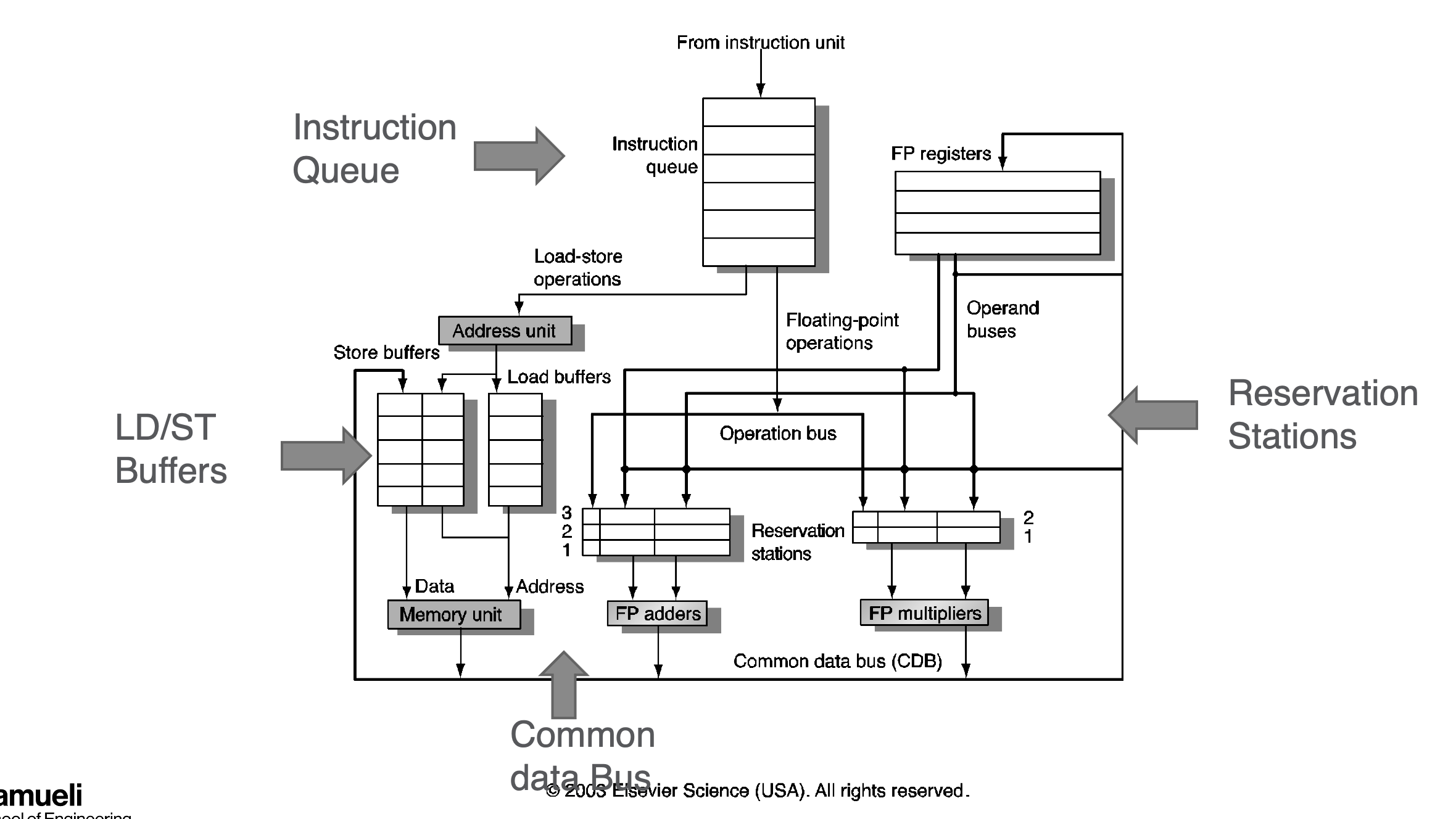
Limitations of Tomasulo
- Common data Bus (CDB) bottleneck
- single broadcaast medium
- sharing aamong functional unit (FU), load/store unit (LSU) and reg file
- contention bw multiple producers and scalability bw multiple reveivers
- long latency broadcast
- performance limit by CDB latency - multiple CDB allow multiple in praallel
Solutions
- split buses: FU, LSU - expensive
- crosbar switch - alo expensive
- point to point connetions
- higher level bus
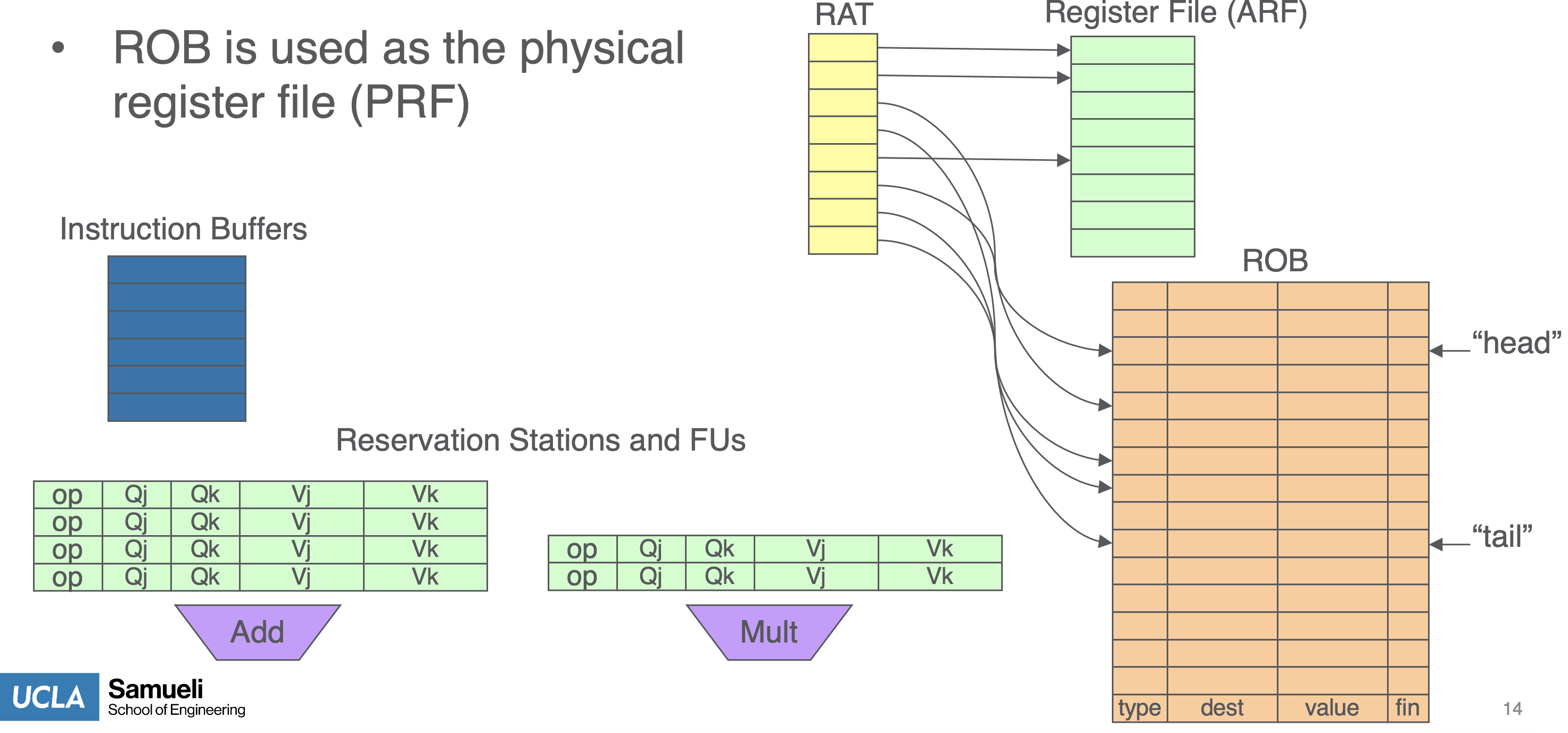
Reorder Buffer (ROB)
- reorder instructions
- e.g., reorder to prevent branch prediction 3 stall
Motivation
- Maintaining program order semantics
- Ensuring that CPU resources accessible to the application are updated in correct order – (e.g. code debugging)
- Facilitate precise exception handling
- Ensuring that only the effects of instructions up to the one causing the exception are committed
- Enabling Speculative Execution
- Separate architected (ARF) vs physical registers (PRF)
- Track program order of all in-flight instructions
- Enable in-order completion / commit / retirement
- basically, ROB tracks head and tail pointer of regs in instructions
- read next instr from instr buffer
- check for structural hazards
- check reservation station and ROB availability
- if none, then stall for hazard
- read the RAT
- find PRF regs given source ARF reg
- the PRF regs are entries in the ROB
- find PRF regs given source ARF reg
- allocate a new entry in the ROB
- ROB is sorted llist
- head points to oldest
- shift tail down
- copy ARF info to new entry in ROB - needed for callback/commit
- update RAT
- if isntr has dest reg
- use rob dest index
- rob_idx => RAT->rd
- then RAT propagates renaming to reservation stations
- dispatch instruction to reservation stations
Execute Stage
- after reservation isntrs issued
- wait for validity of source operands
- operands updated via CDB (common data bus)
- proceed to execution once all operands ready
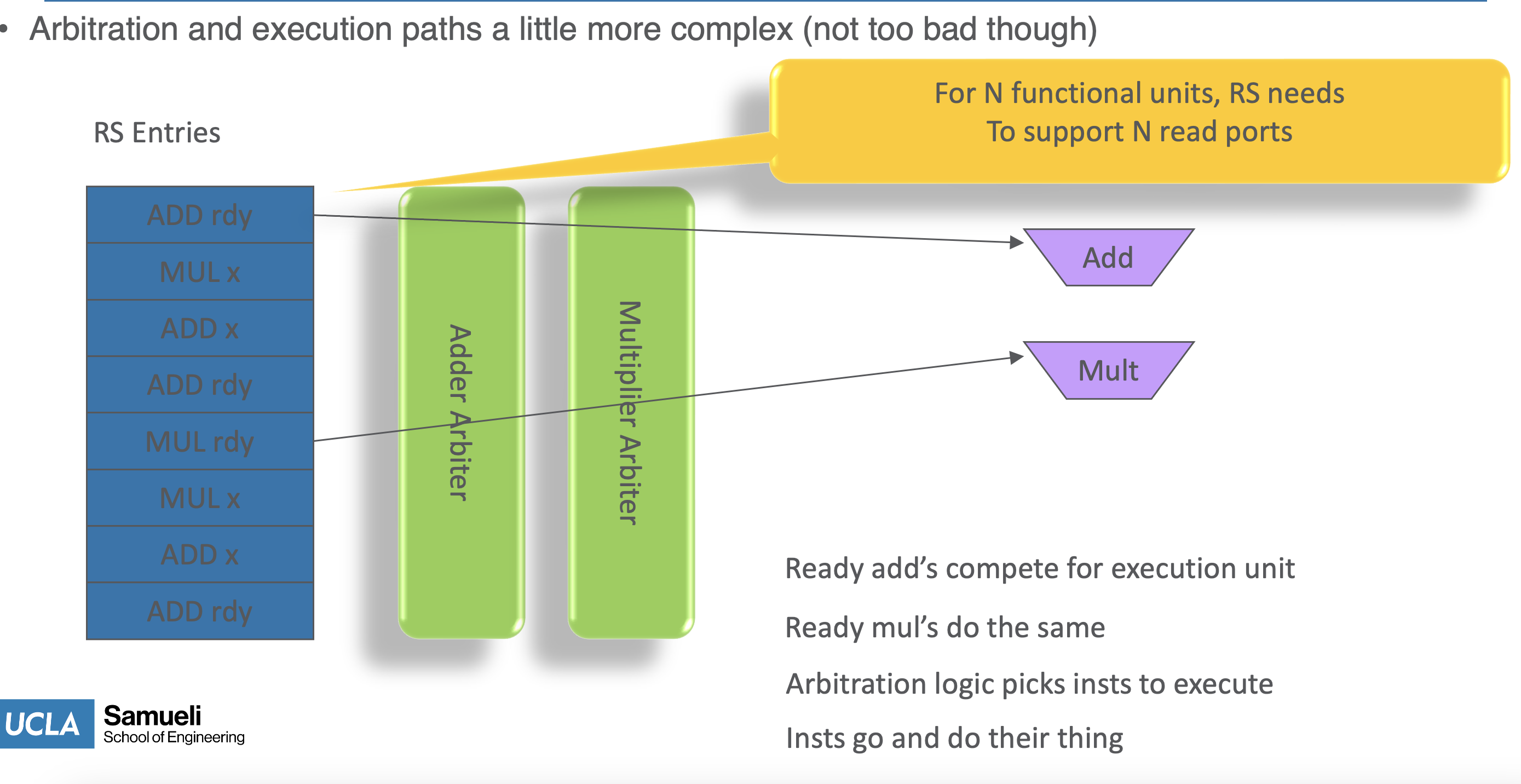
- arbitrate selection of instr if multiple ready at RS (reservation stations)
- then 1 RS intr is sent to ALU
Write
- broaddcast result on CDB and update RS instrs
- dont update ARF
- update ROB
- mark ready bit in rob to signify the instr has completed
- free RS entry
Commit
- wait until ROB’s head pointer’s ready bit is valid
- then write that back to ARF (update RAT) or update MEM
- shift head pointer down
- then wait until that ready bit is done
- what the user sees:
- although C, F, G all executed before A, A’s ready bit in the ROB was not valid until now so it only gets reflected in ARF after it validates
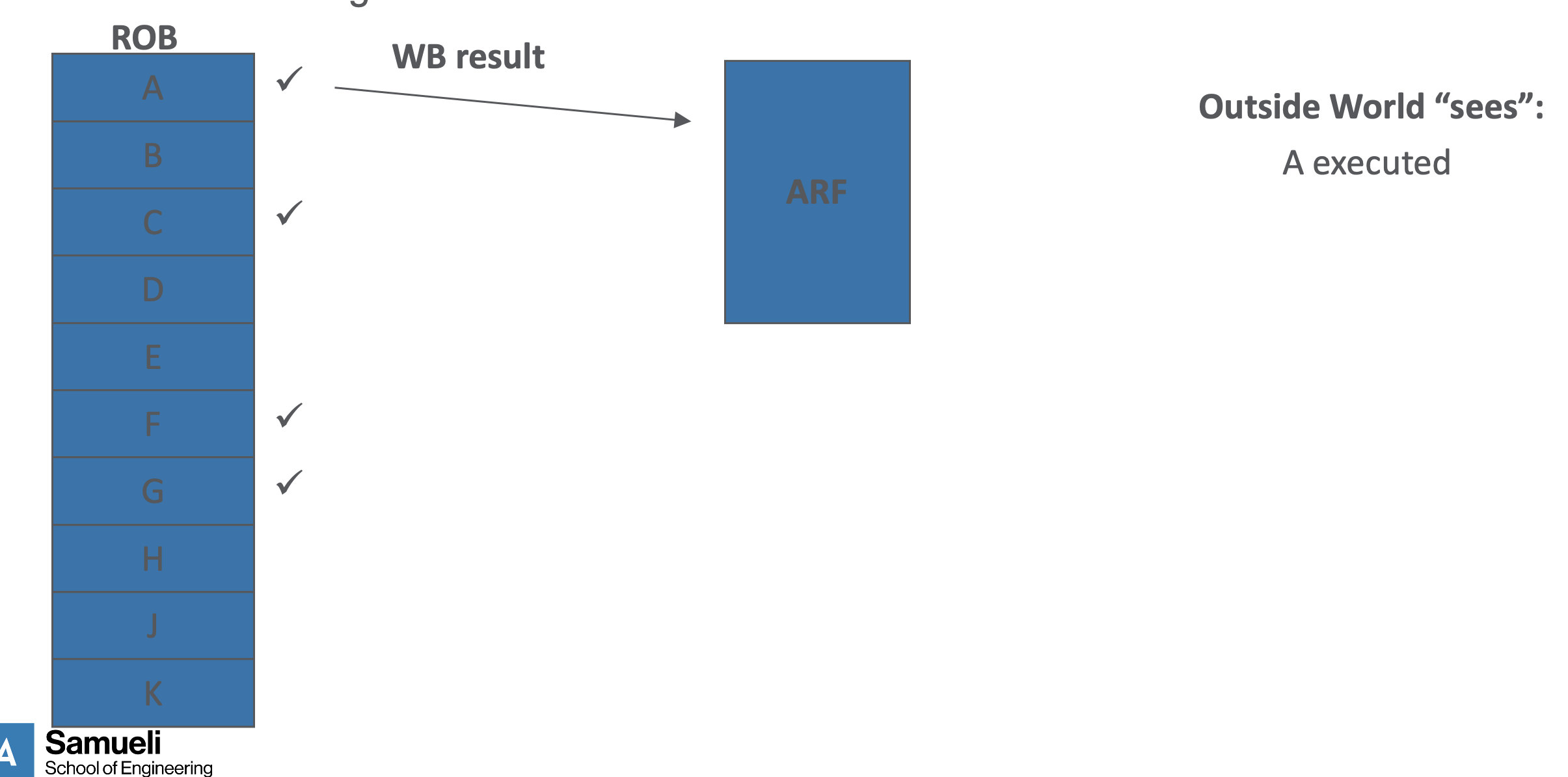
- thus internally it is OOE but user still sees in order exec
- although C, F, G all executed before A, A’s ready bit in the ROB was not valid until now so it only gets reflected in ARF after it validates
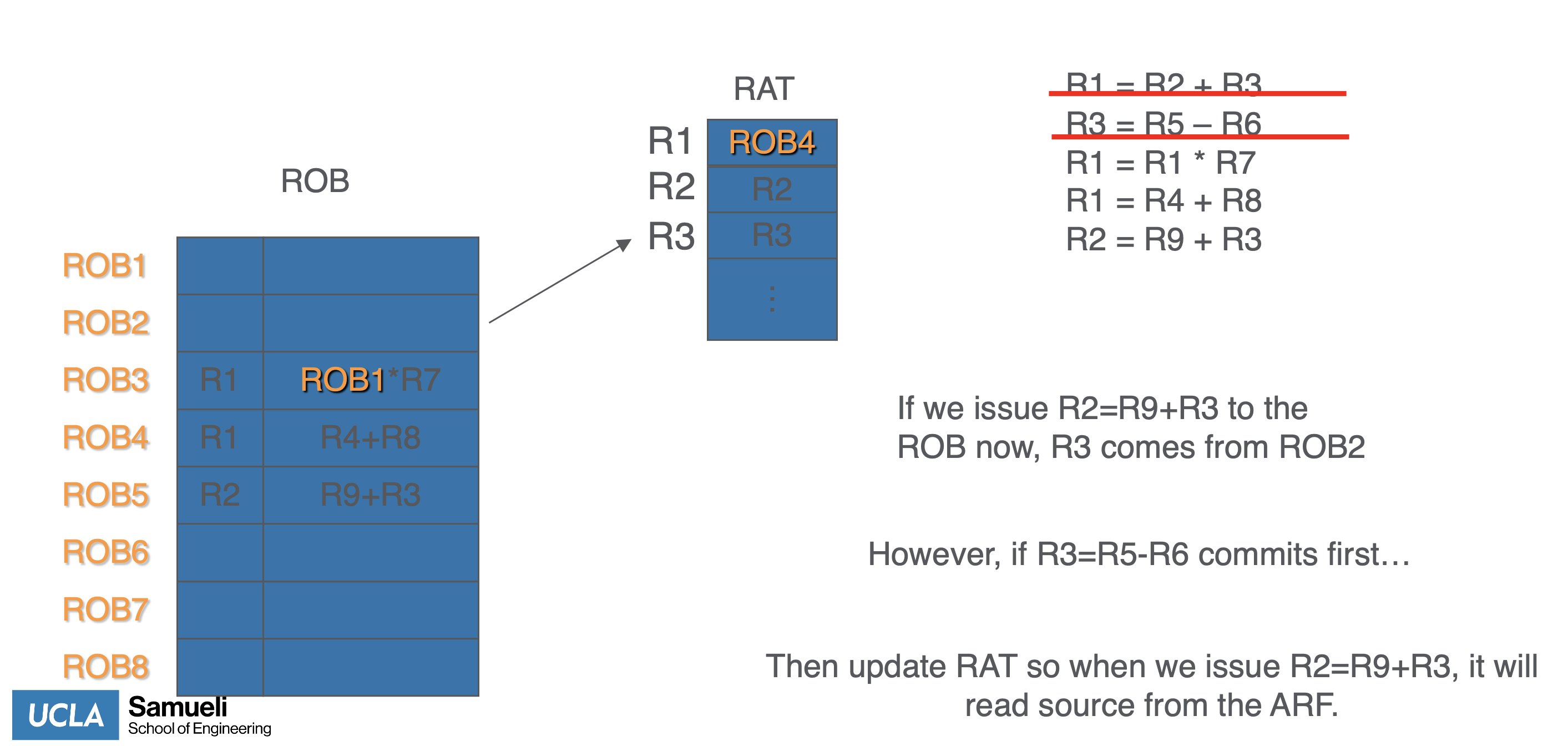
- Register renaming using ROB
Unified RS
- instead of an RS for each add/sub and mult/div, use one unified RS
- arbitration must be done to determine which ALU to go to from the URS
- CPU limited to 1 IPC issue
- commit needs to happen >1 IPC to be sustained on superscalar
Faulty Solution: Dual (N) Issue
- need to check resource availability of RS and ROB for 2 intrs ata time
- then needs to do dual renaming
- simple unless RAW hazard:
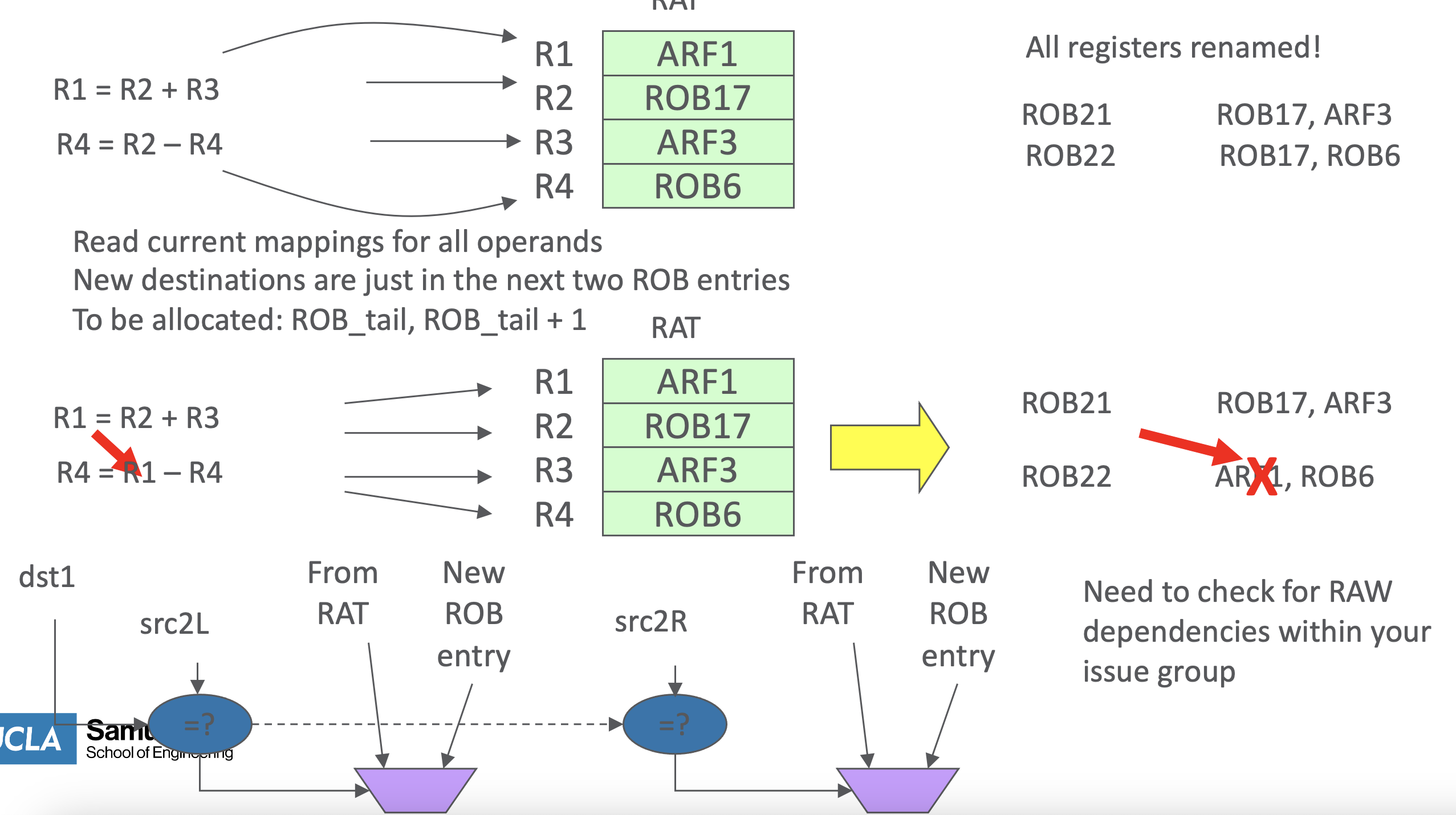
- if there is RAW the dependency prevents parallel renaming
- simple unless RAW hazard:
- then update RS/ROBs in parallel
- thus its expensive to heck for RAW for renaming for more than 4
Multiple CDB
- what is used today
- but requires RS entry to check operands acros both CDBs’ ROB/RAT
- thus for >1 IPC we need multiple read ports on ROB and write on ARF
Checkpointing
- Create checkpoints of RAT, if one succeeds then delete other chckpoints:

Handling LD/ST
- handled separately bc cycle count is not deterministic and store is unpredictable
- so we want to limit loads and eensure stores in order
Solution: queues
- LD/ST queues
- if LD ST is the same address and we observe ordering, then we can use loads from previous loads and stores in order
- memory update in order via ROB
- we determine address through ALU or independent Address Unit
Stores
- wait for source operands
- write value into table (queue)
- wait for address
- write address into table
- then exec
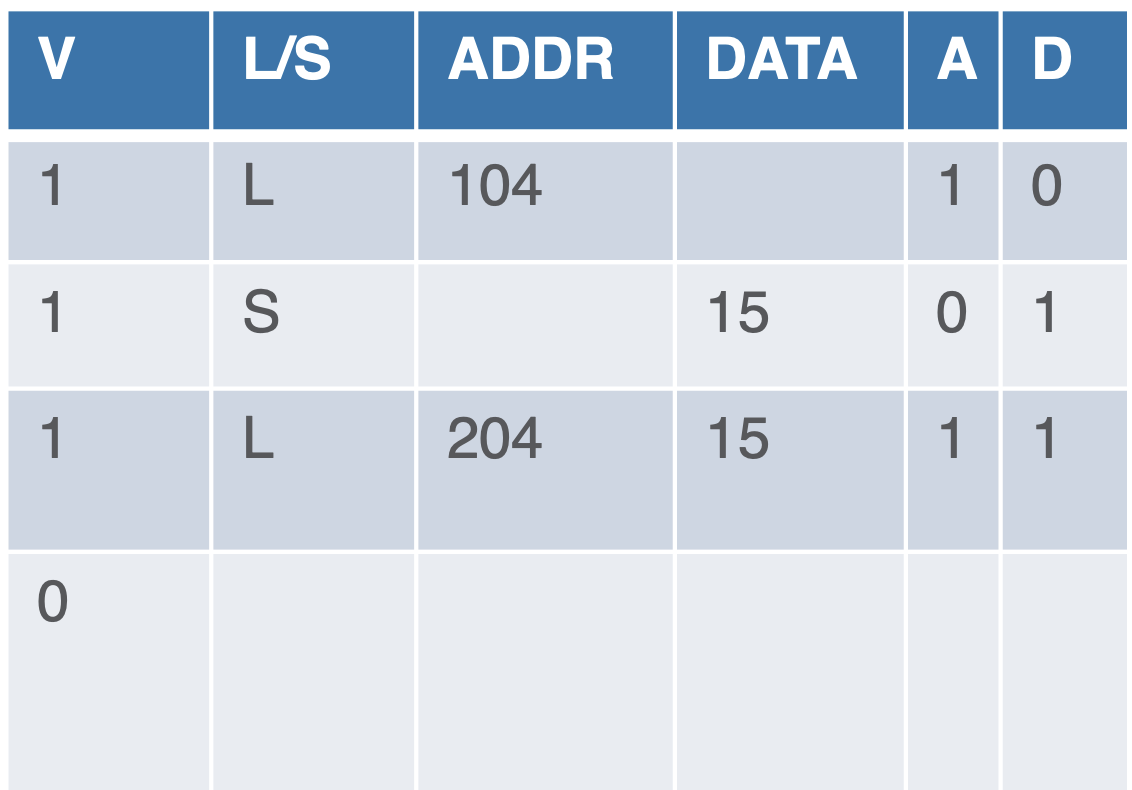
Load
- wait for address
- write to table
- search for earliest LD/ST of same address from queue to avoid another trip
- write value to table
- broadcast value via CDB
Optimization
Forwarding
- Ready load with same address
- Forward value
- Ready store with same address
- Forward value
- Pending load with same address
- Wait
- Pending store with unknown address
- Wait or speculate (forward value)?
- Otherwise
- When load complete, check the store address
- If different address, we proceed as usual
- Otherwise load forwarding
- Drop the fetched value
- Doesn’t happen often
- Common solution