8 - Instruction Pipeline
ucla | CS M151B | 2024-02-01 16:11
Table of Contents
Single Cycle CPU
- single cycle iin series, no parallelism
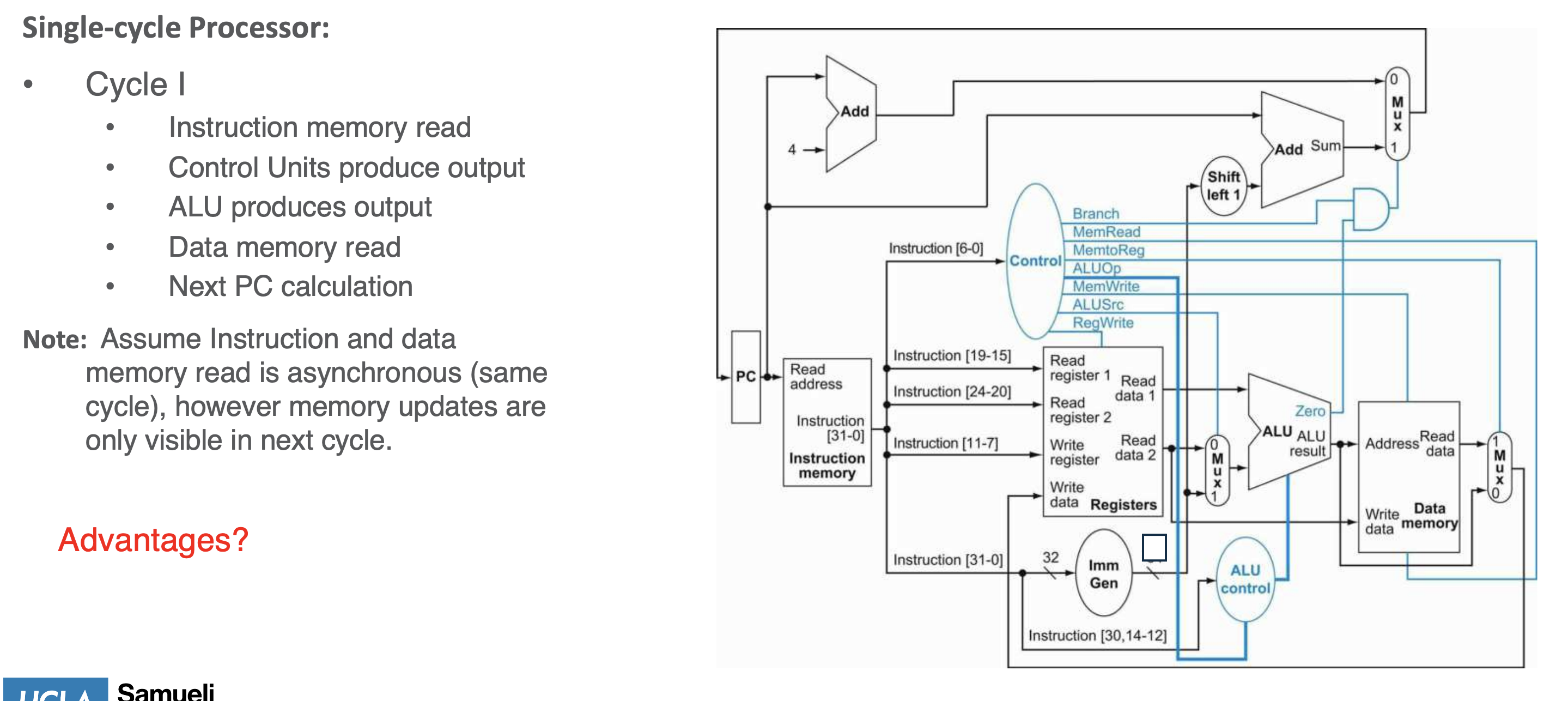
- simple design, efficient
- but long latency due to longest propagation delay due to signal loss
- latency affects cycle time -> slower CPU time
- solution: multi-cycle pipelining
Multi-Cycle Processing
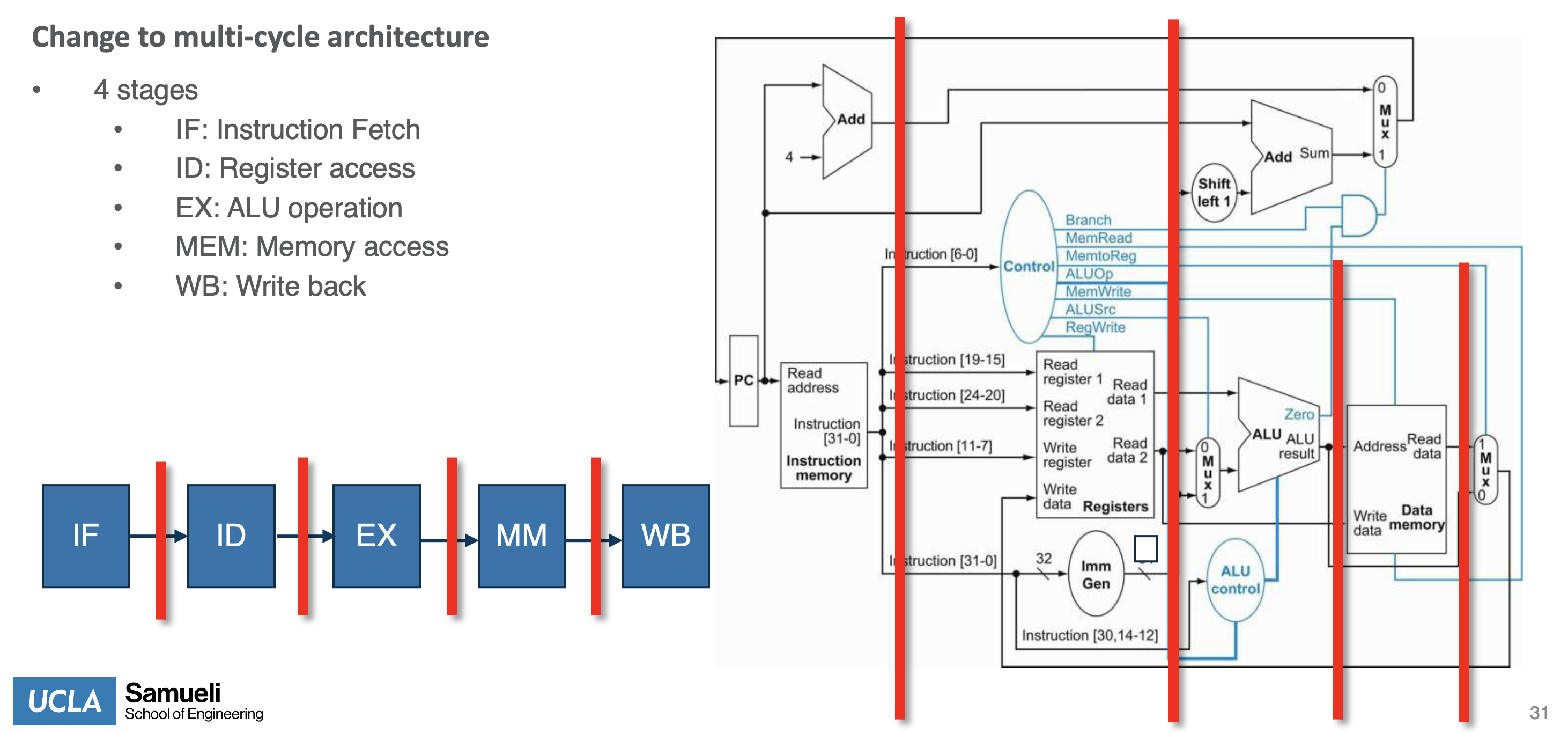
Improved Propagation Delay
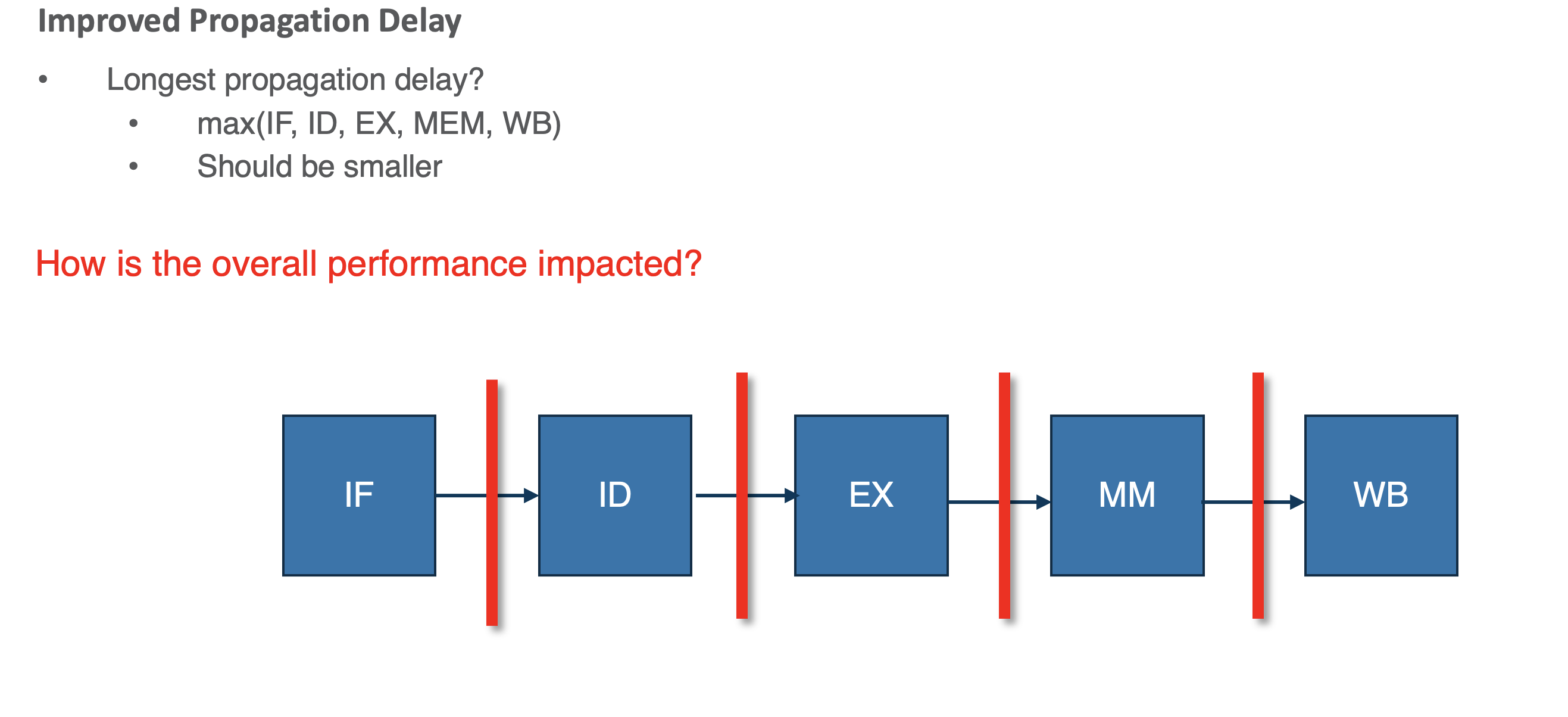

Limitations
- hardware undeer utilization -> idle cycles during operations
- solution: pipeline
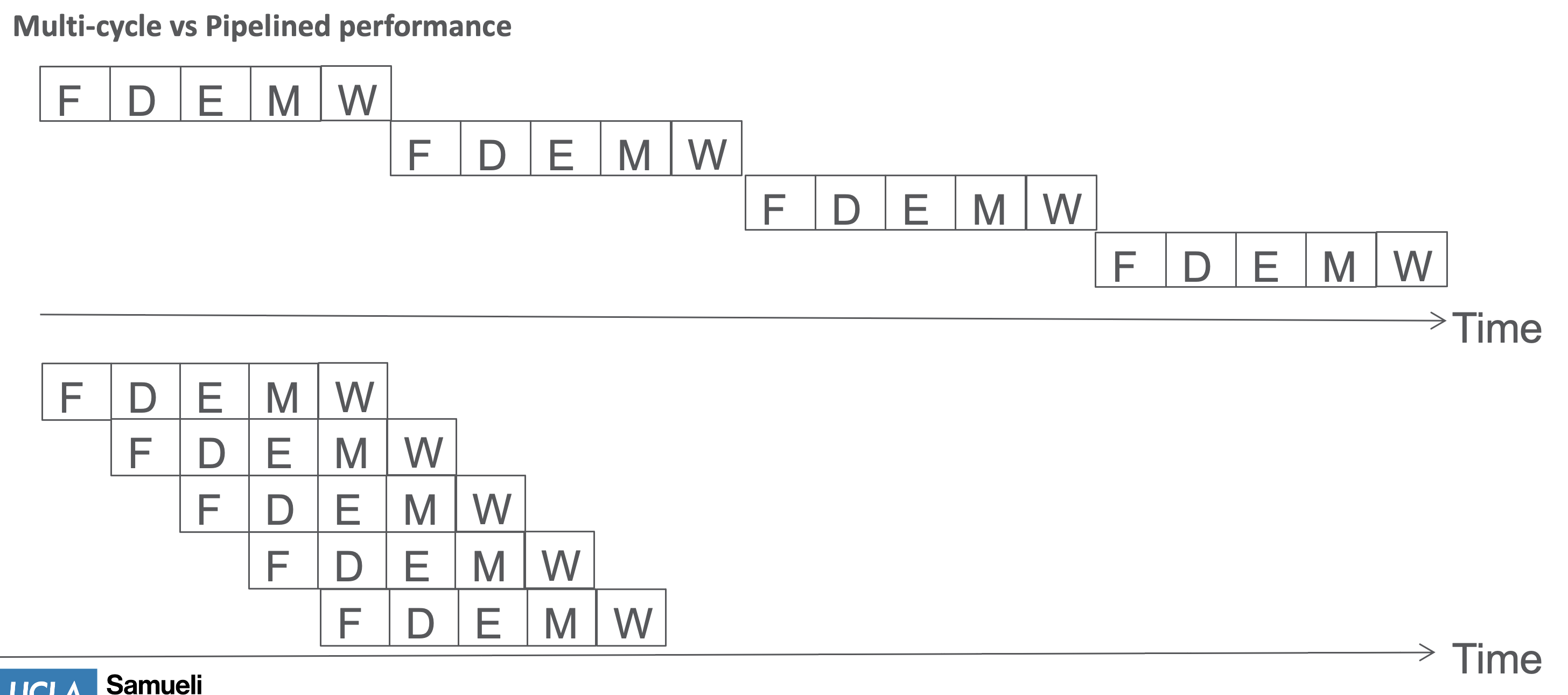
Pipelined Processing
- fetch a new instruction each cycle
- PC incremented each cycle
Performance Advantage

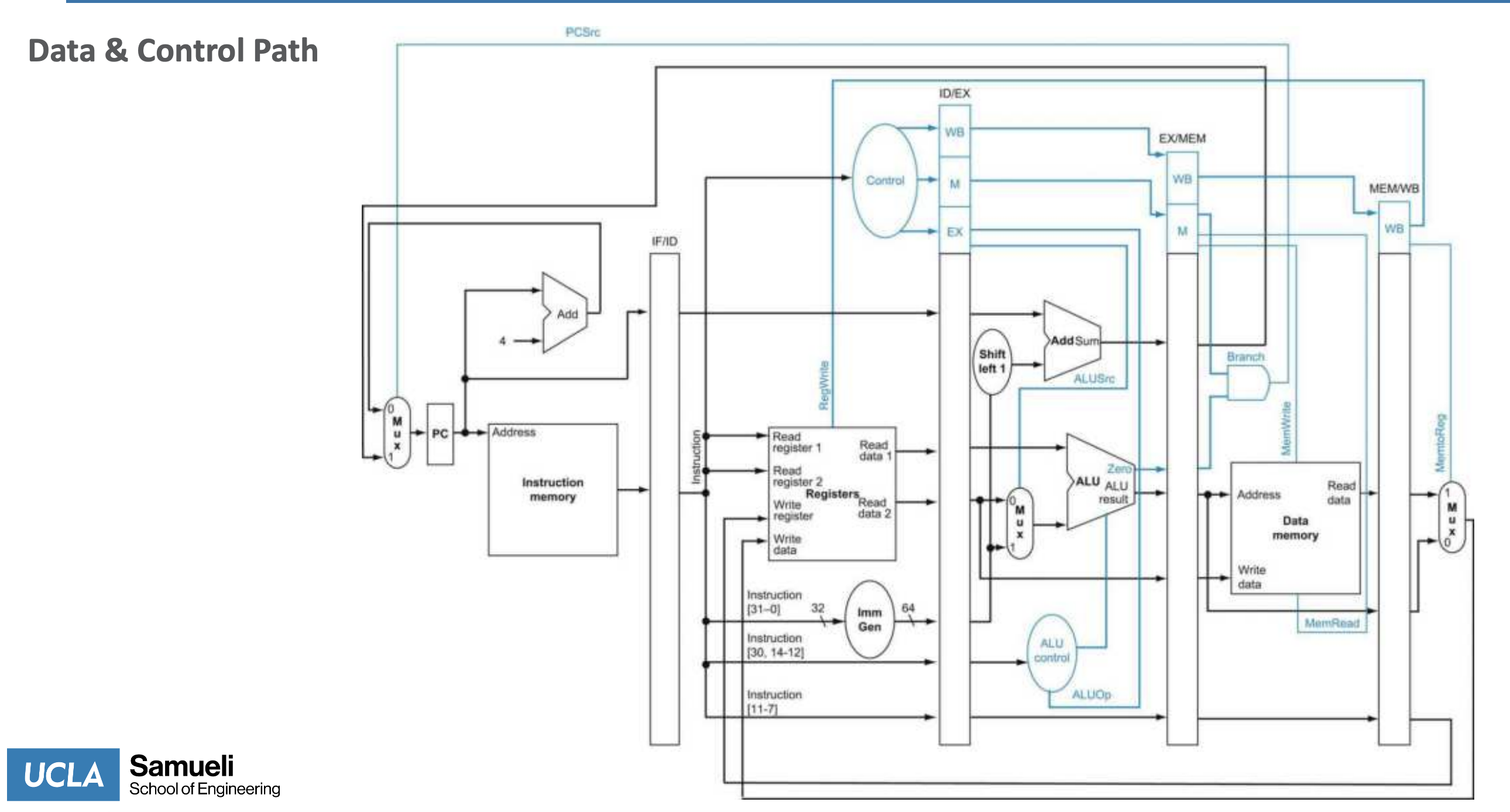
Pipelined Architeture
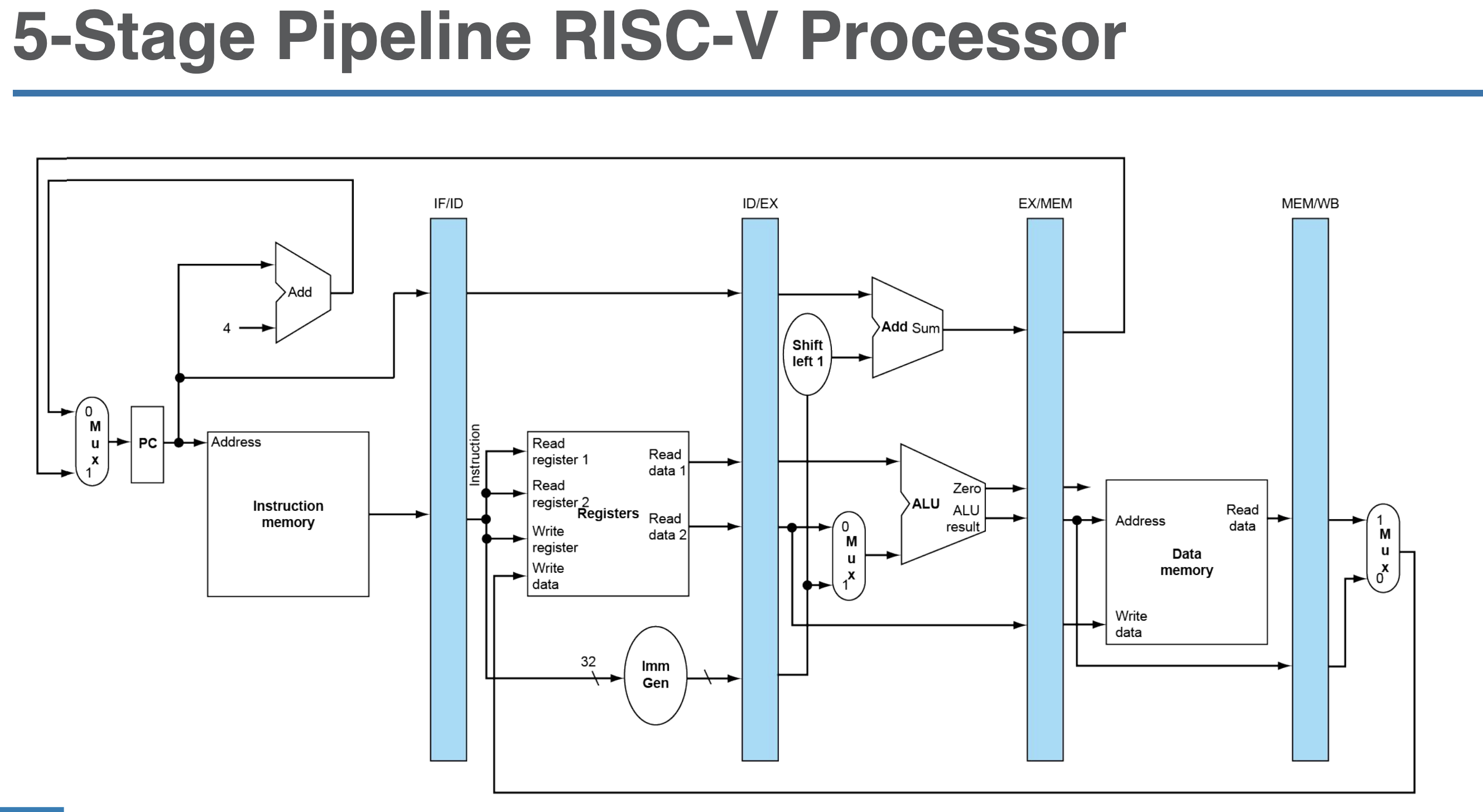
- set next PC and instruction to control at each cycle
Example Run
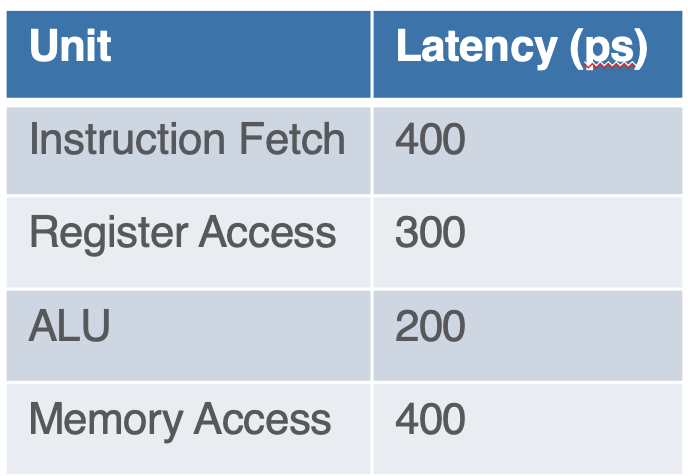
Latency
- given base intruction cycle times
- we can find single cycle latency as
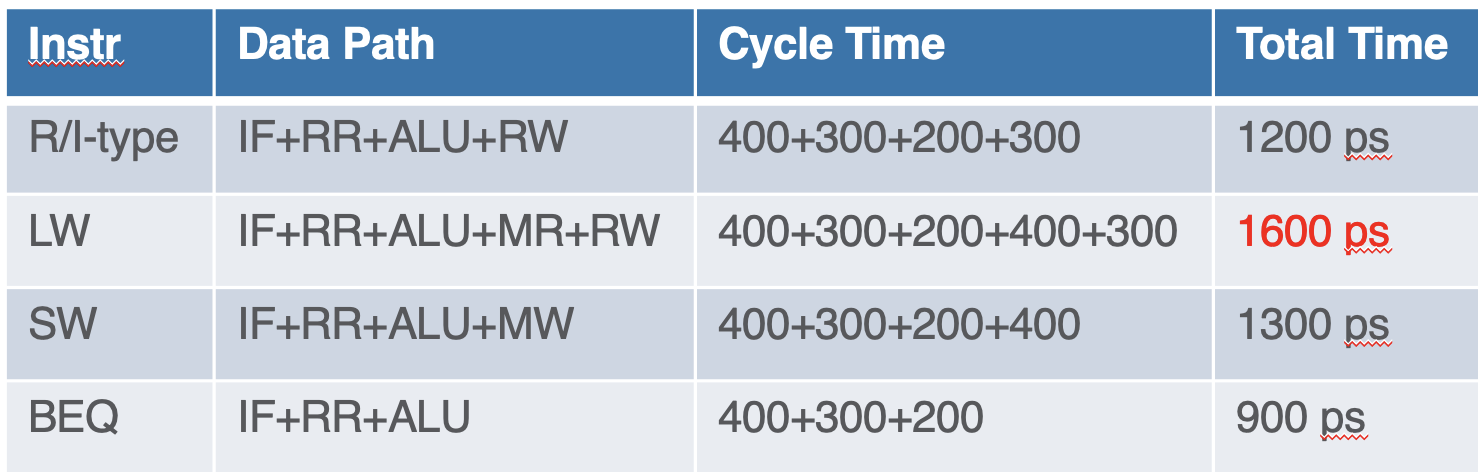
- while multi-cycle pipelined is
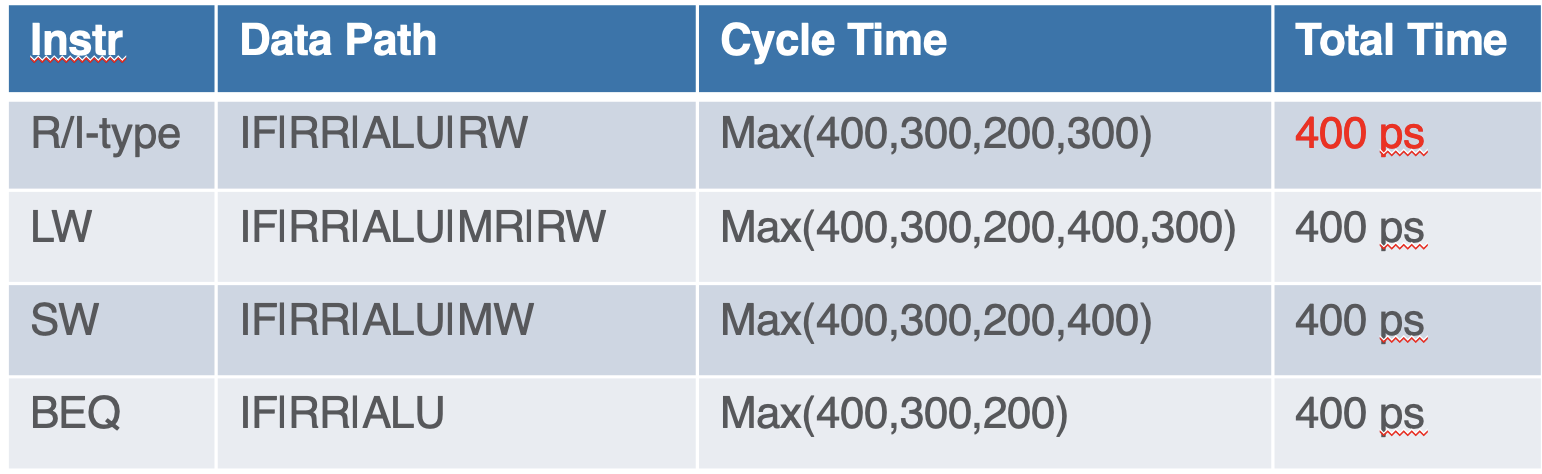
- although the latency is reduced, there are issues with register dependency
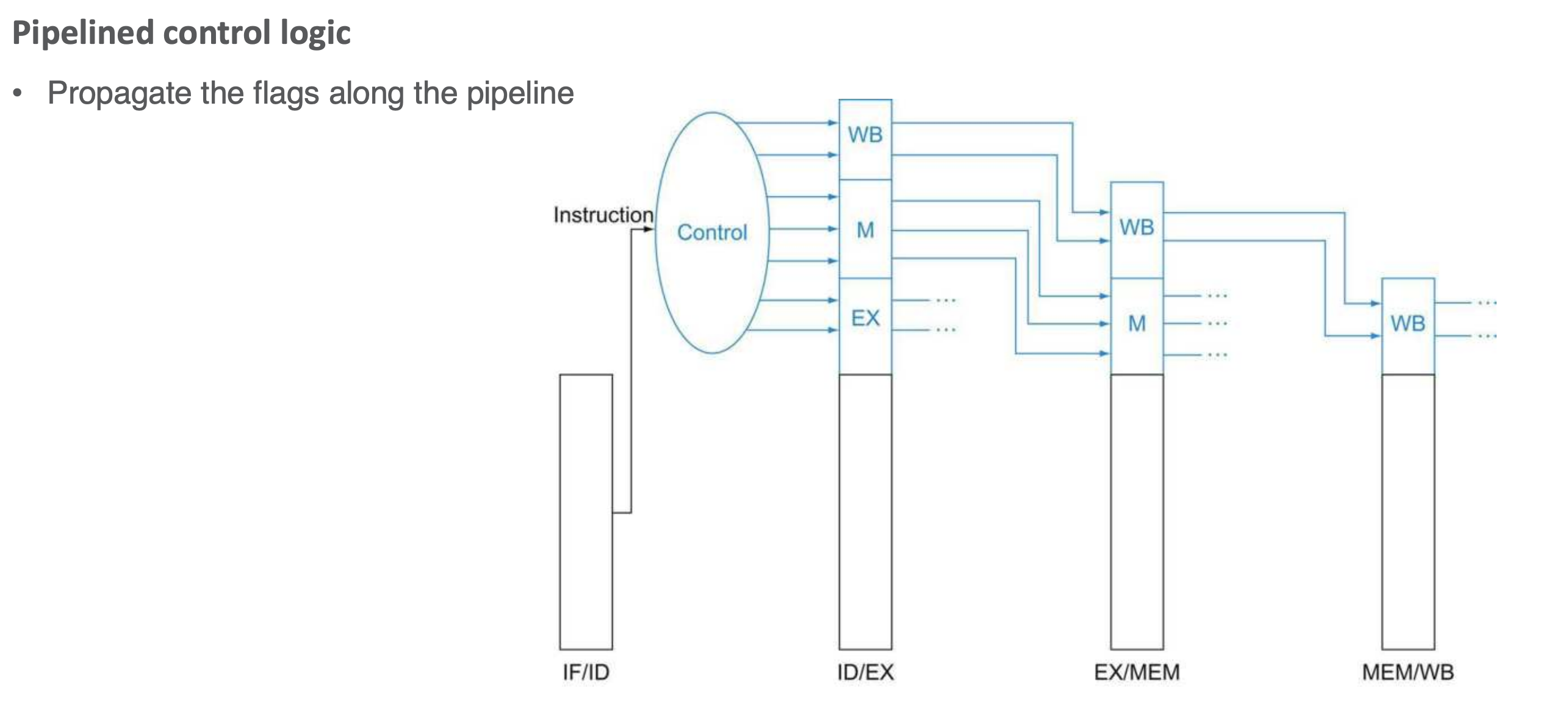
Pipeline Hazards
Register Dependency
- pipelined instructions disturb the sequential assumption of execution
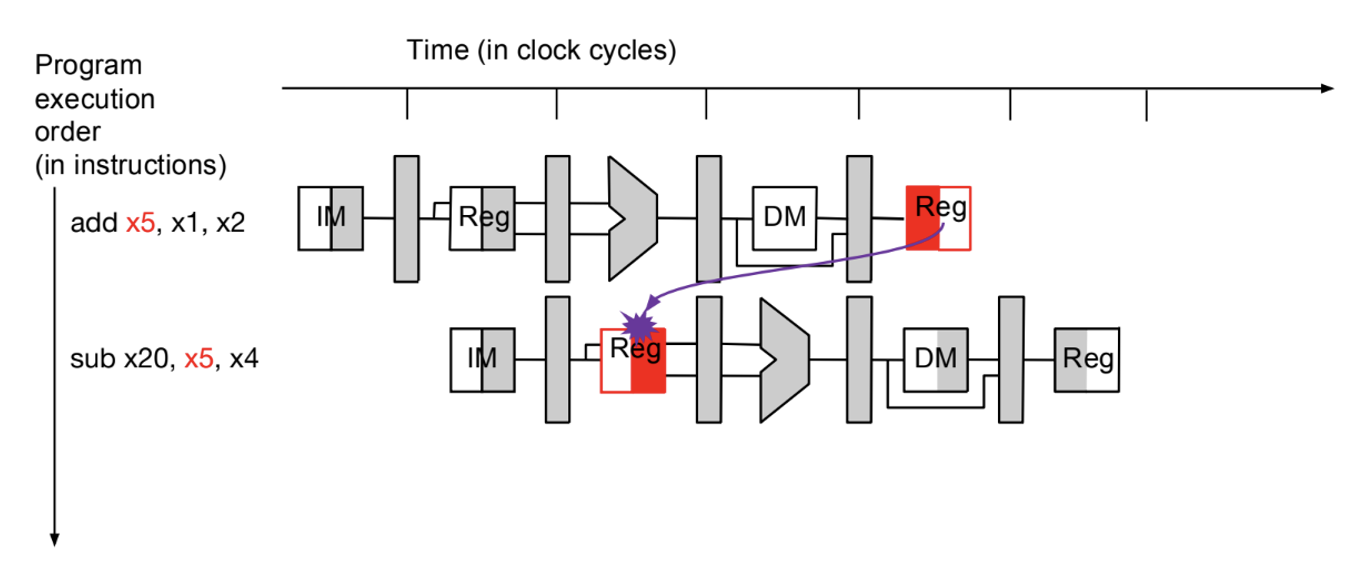
Control Hazards
- control flow dependency b/w instrs
- condition or branch addr may not yet be available to read
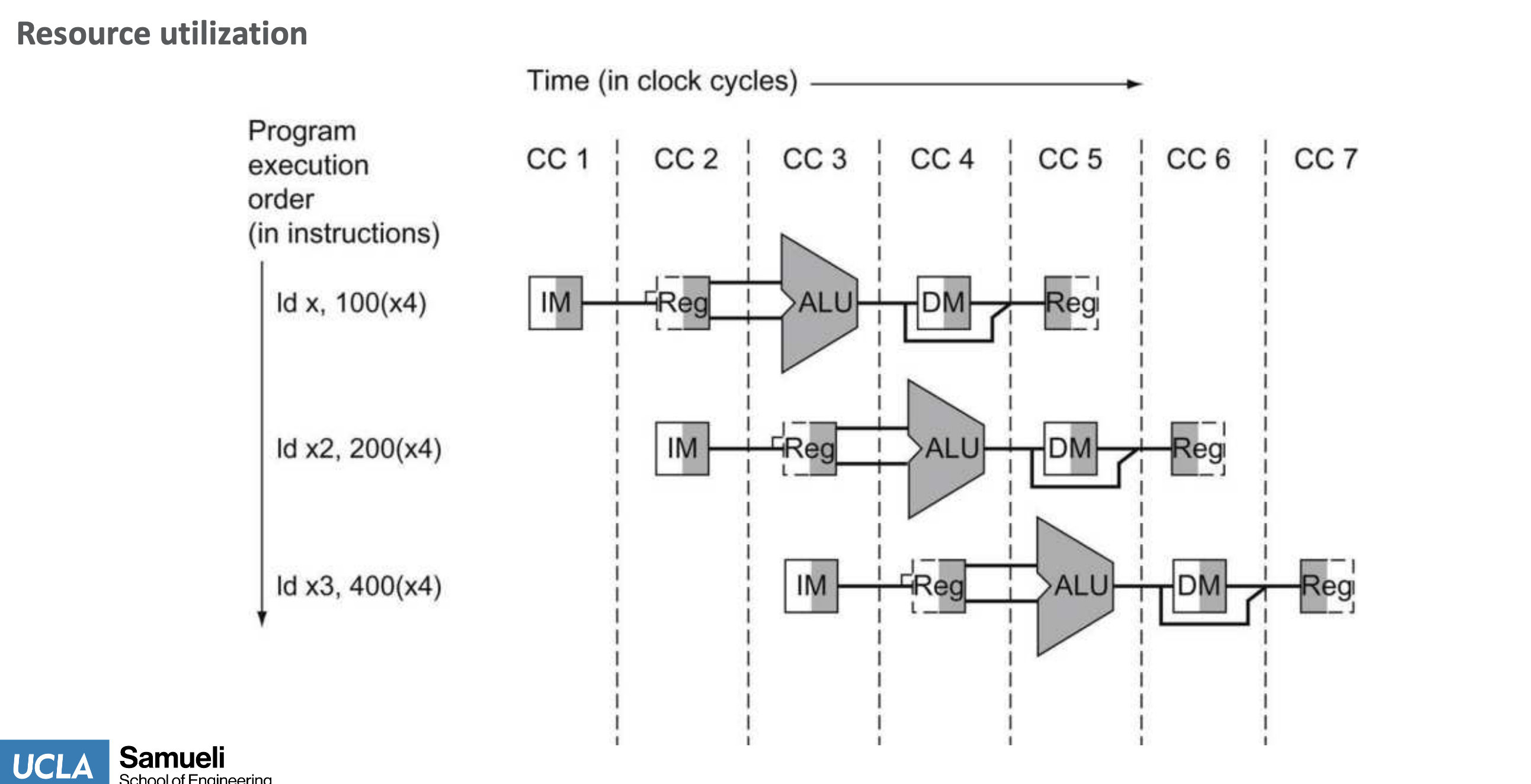
Structural Hazards
- resource sharing b/w instrs - prior instr using a resource needed by next instrs
- specifically about the h/w sharing
- e.g., multi-cycle divide
Data Hazards
- register sharing b/w instrs
- prior operands req by next instr
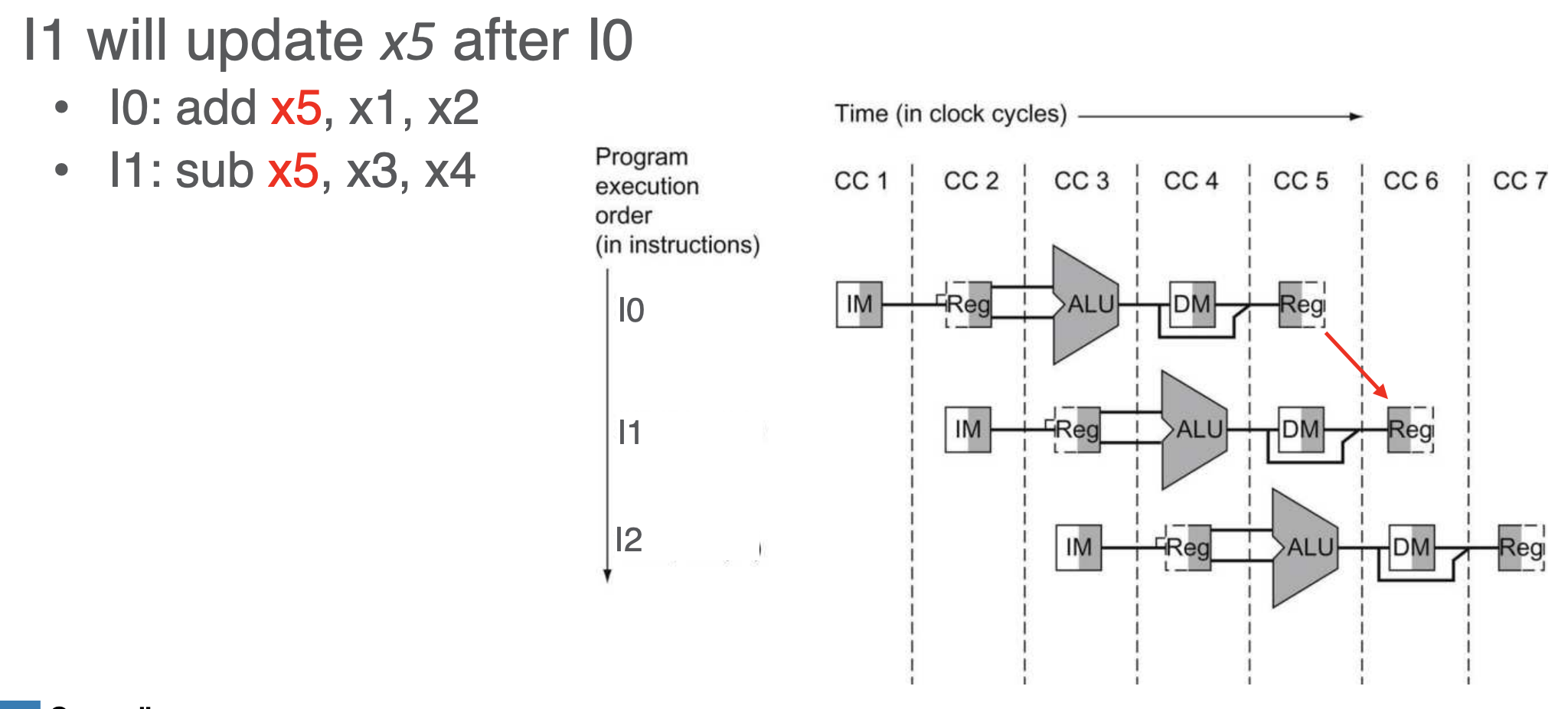
- read after write (RAW)
- an issue bc read and write from same register but cycles apart is an issue
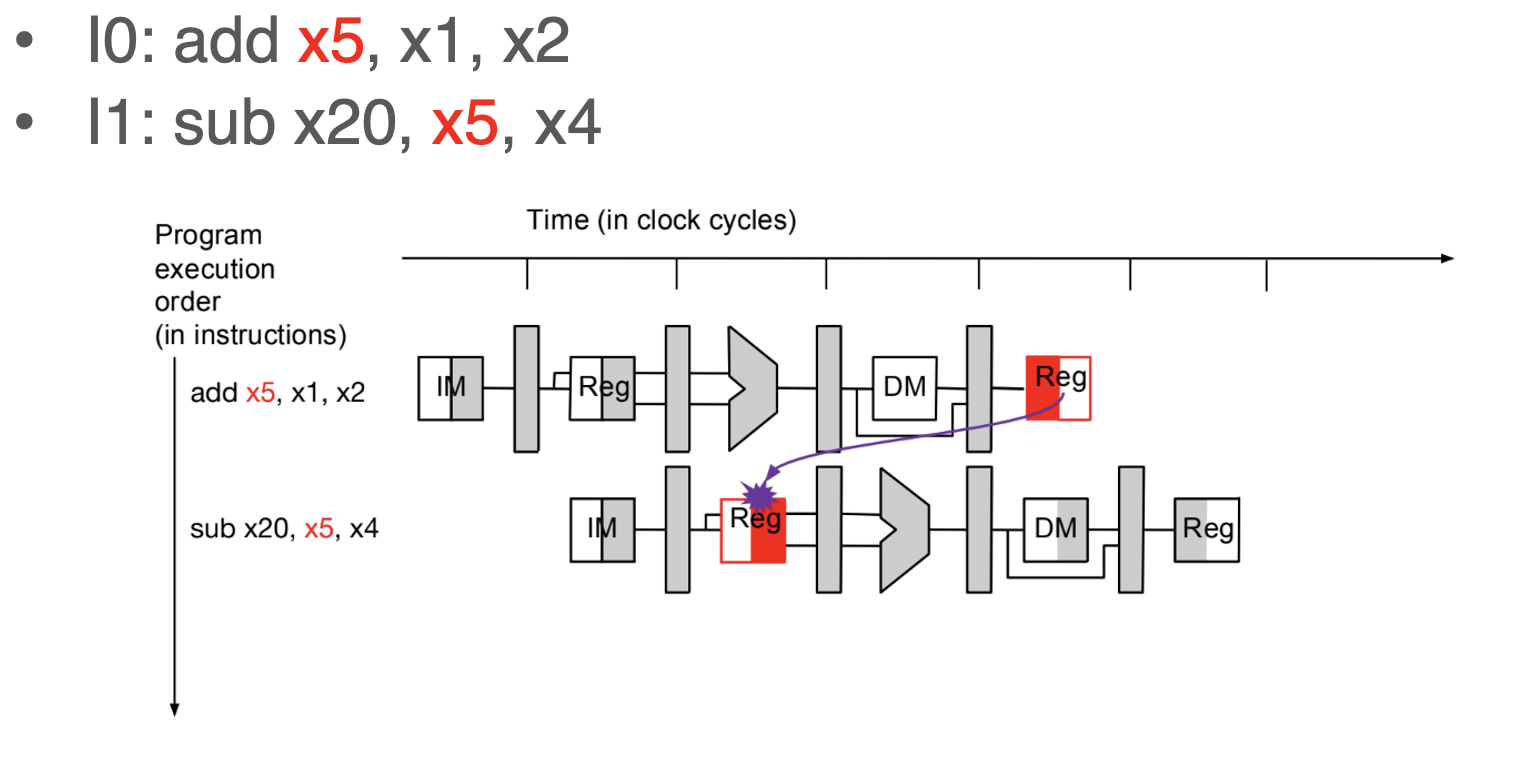
- an issue bc read and write from same register but cycles apart is an issue
- write after write (WAW) - not an issue
- 2nd write happens a cycle after so no worries (in-order execution, issue if out of order)
- 2nd write happens a cycle after so no worries (in-order execution, issue if out of order)
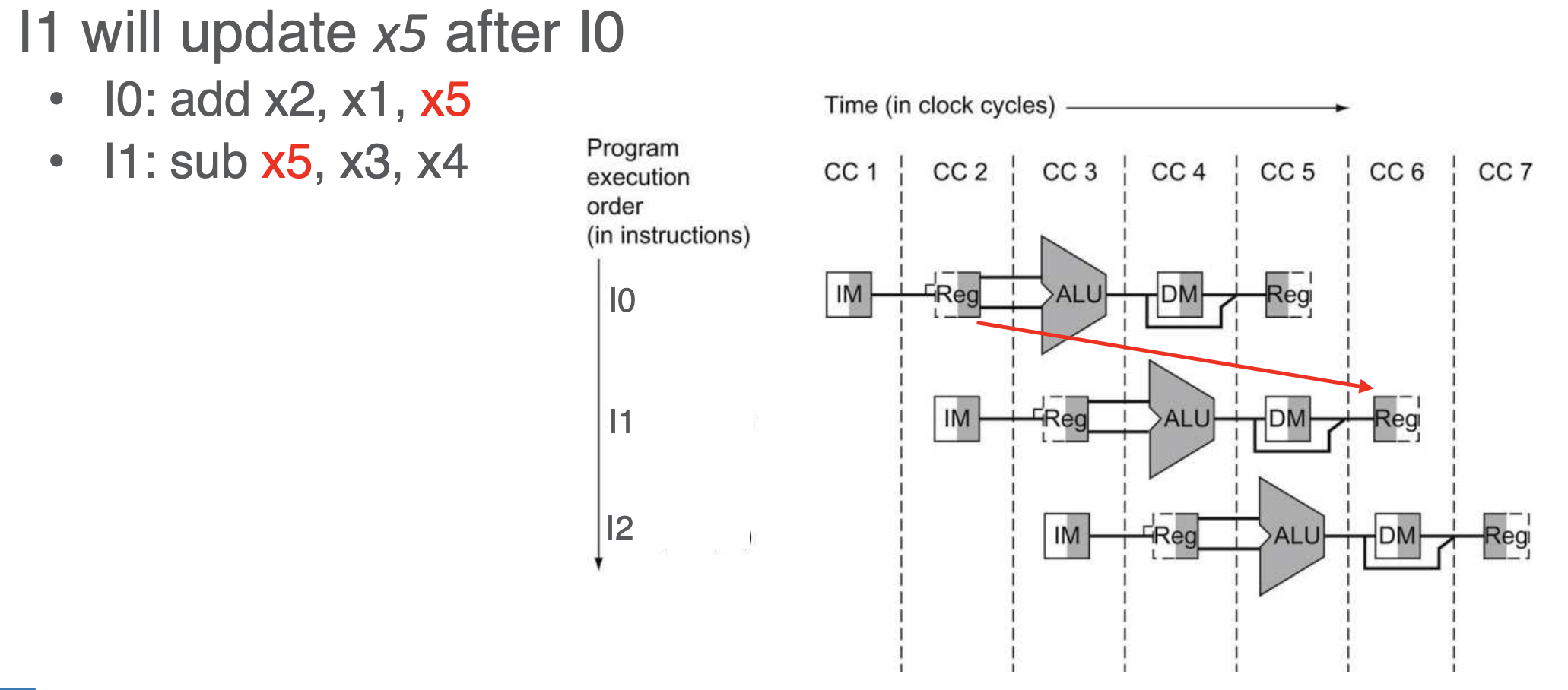
- write after read (WAR) - not an issue
- not an issue due to in-order execution (due to separation in cycles)
- not an issue due to in-order execution (due to separation in cycles)
- read after read (RAR) - not an issue
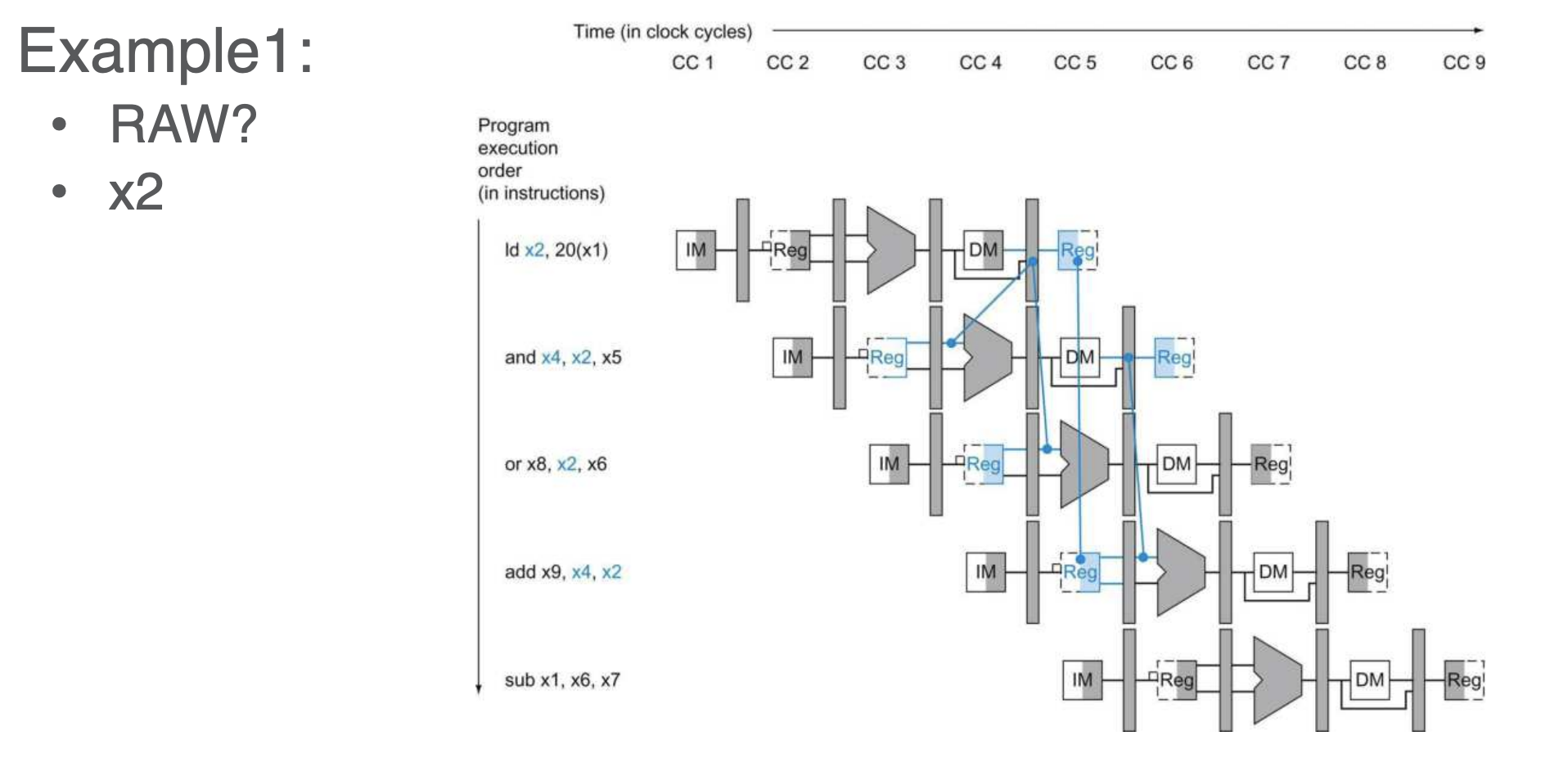
- given this RAW example
- naive approach - stallling the pipleline
- inserting a NOP - i.e., invalid op “bubbles” the register so it is not accessed until after the NOP
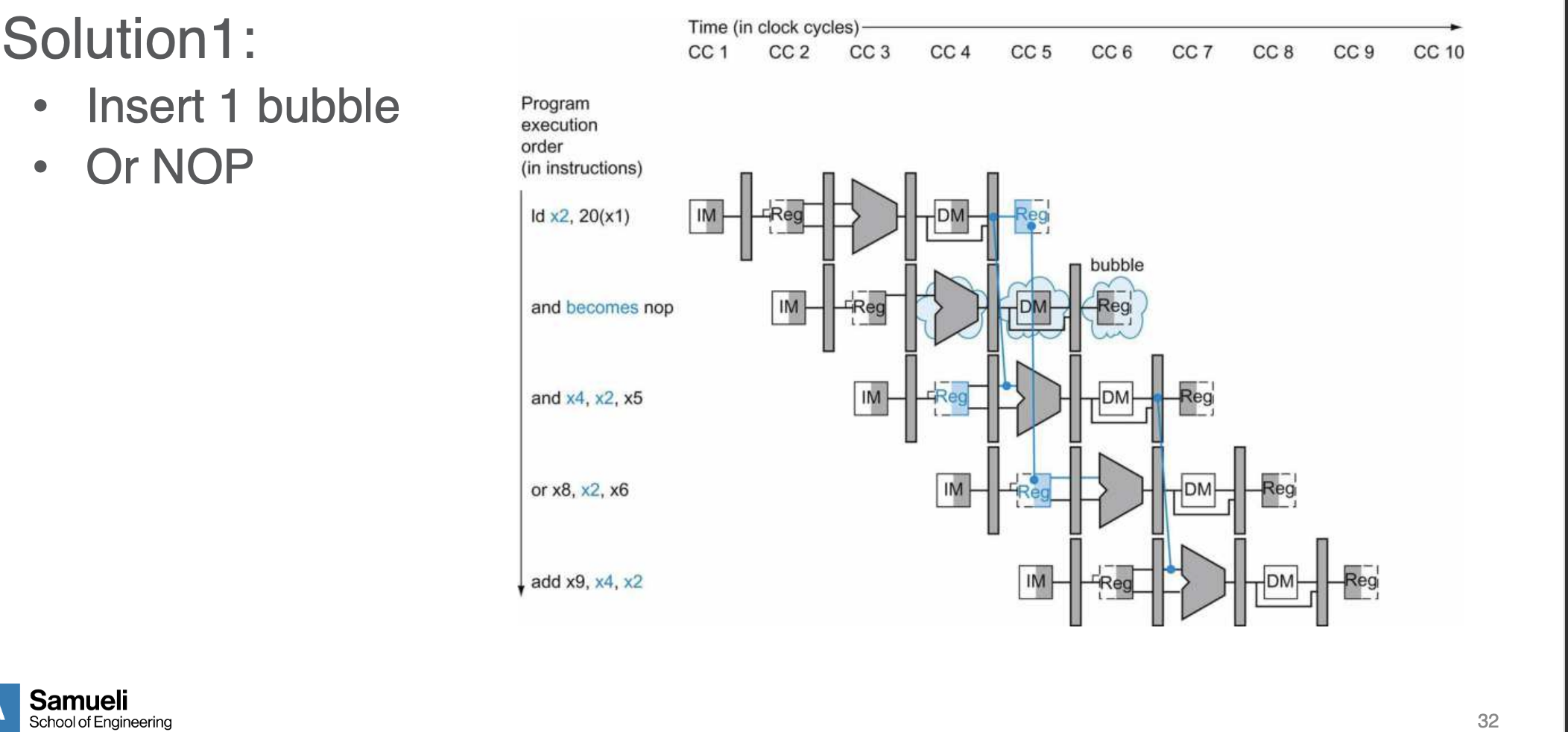
- inserting a NOP - i.e., invalid op “bubbles” the register so it is not accessed until after the NOP
- smarter solution - Data Forwarding
Data Forwarding
- include a wire (set high by a flag indicating RAW) that ties directly to the ALU that reads from the written reg
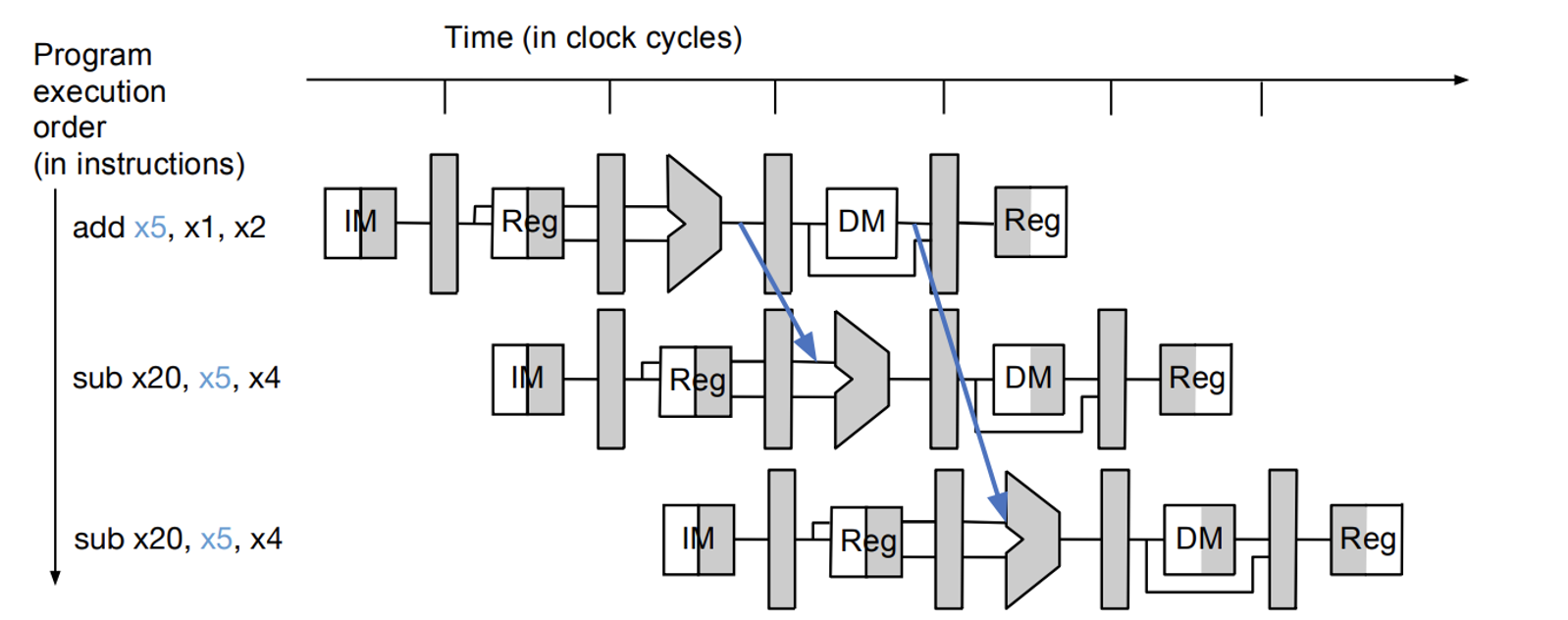
- then MUX the source to the ALU bw the I1 op or the reg from I0 forward
Cost
- must add a wire from prev instr state to next state
- also need a mux to select source
- increases propagation delay
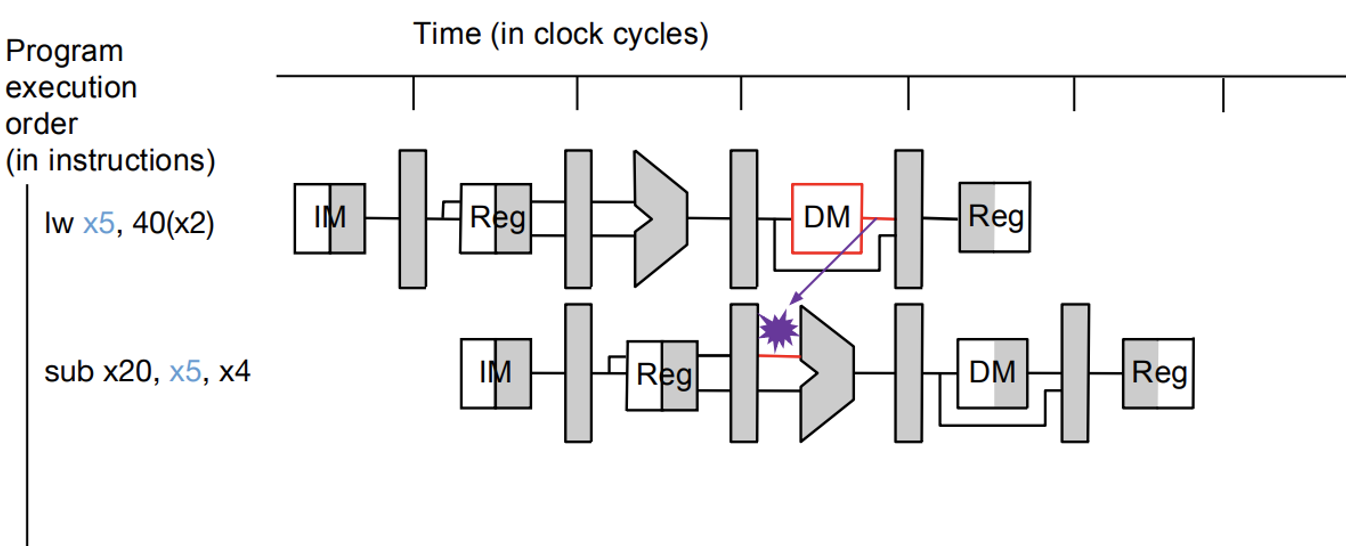
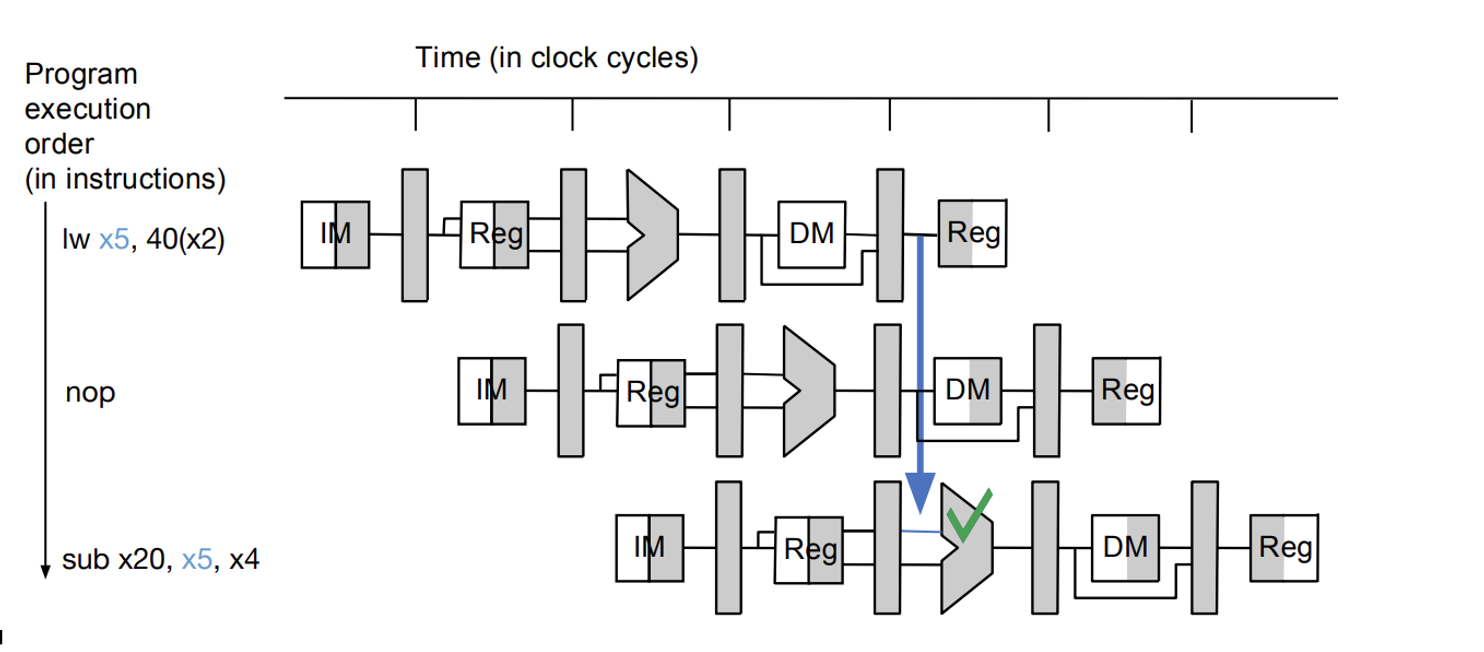
Data Forwarding: Memory ALU
- direct wire is not practical when reading from data due to propagation delay
- in these cases we can add a NOP in between to reset the clock
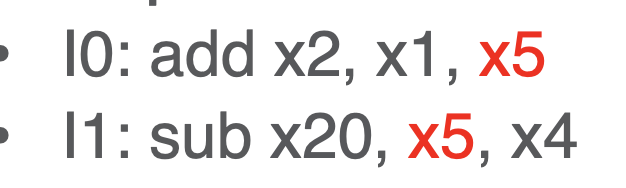
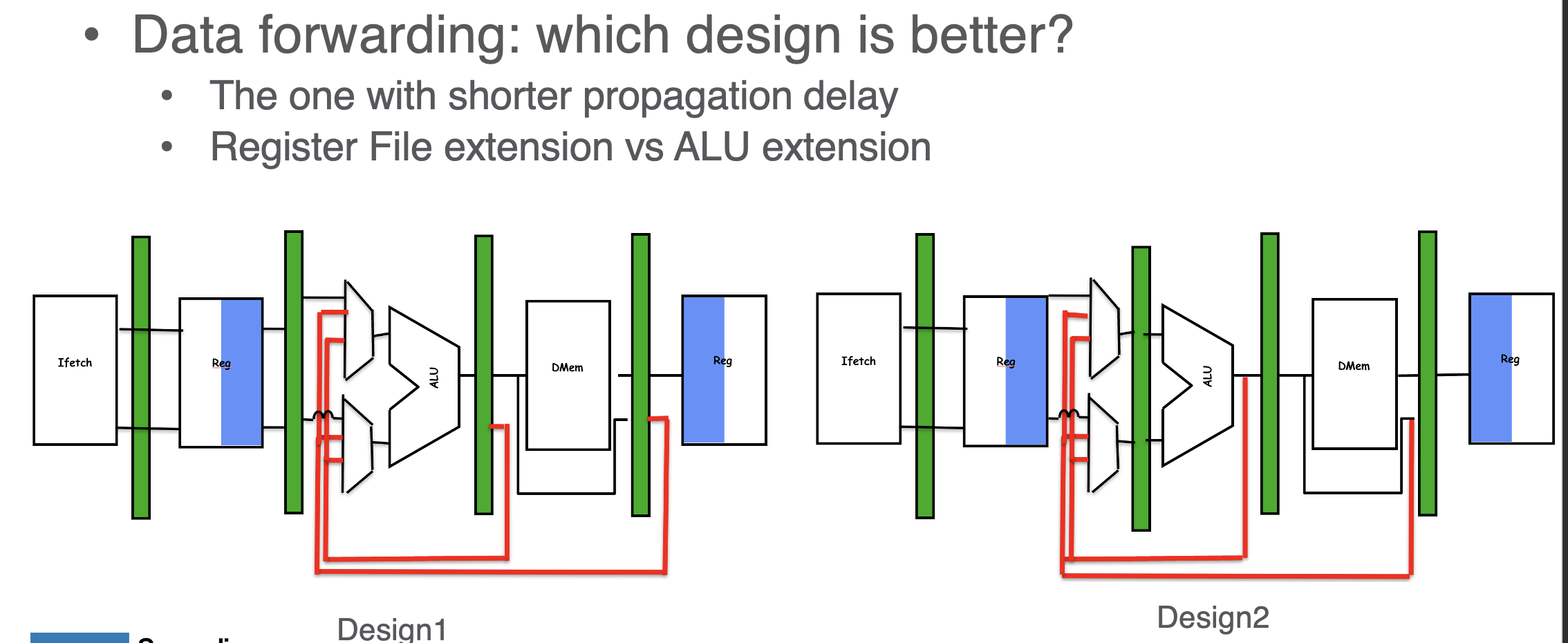
General Designs
- we decide the design based on propagation delay; reading from reg is expensive so adding mux is not great; instead we add after ALU bc propagation delay is low
Selecting the MUX when data forwarding is required
- look ahead to chek if the destination register is the same as the source for the next pipeline stage
- then also look ahead for the other source/destination register of the second command -> LOR these then decide to handle if HI
- then either add a NOP or set data forward select to HI
- we can decide this using a combinational module at the pipeline stage that sends the select immediately before the execution i.e., in design 1, at the green bar after the ALU or the green bar after the Data Memory