12 - Part of Speech Tagging
ucla | CS 162 | 2024-02-26 08:03
Table of Contents
- Background
- Sequence Tagging Problem
- Classification - Noun Phrase (NP) Chunking
- Hidden Markov Model (HMM)
- Viterbi Algo (Inference)
- Maximum Entropy Markov Models (MEMM)
Background
- effort to add is high so usually not used
- when used, usually as features
Ambiguity
- each sense of a word can represent a diff POS tag
- Most word types (the unique word) are not ambigous (only 11.5% are)
- BUT, most word tokens ARE (40% are)
Baselines
- average tagged disagreement on HF is 3.5%
- baseline i pick the most frequent tag for that word type - 90%
- rule based: human rules based on knowledge of linguistics
- learner based: trained on human created corpora like Penn Treebank
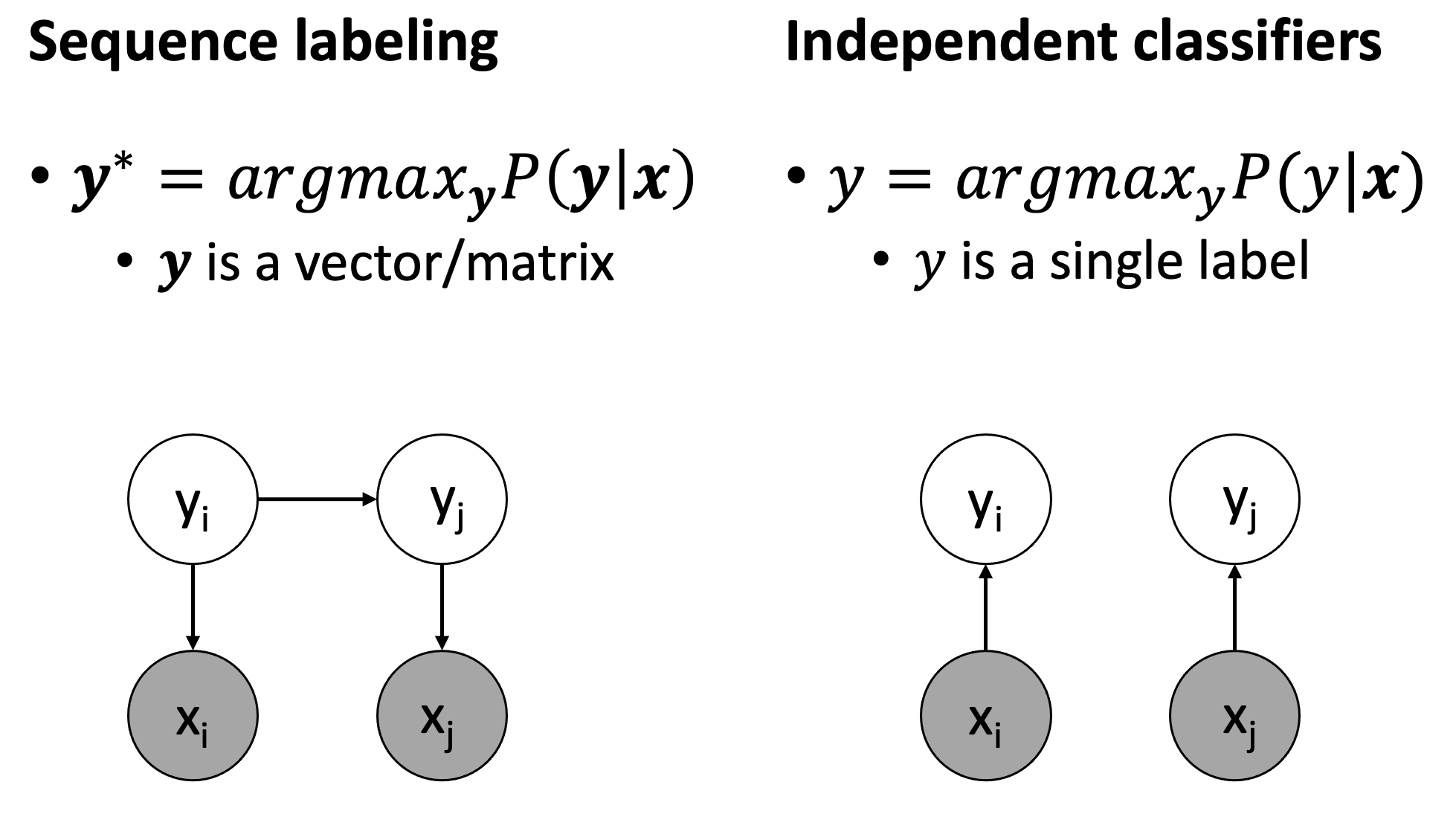
- each token (word) in a sequence is assigned 1 tag
- tags are usually dependent on their neighbor tags
- so, w may use classification model but w lose dependent info in tagging
Classification - Noun Phrase (NP) Chunking
- group together noun phrases
Shallow Parsing

BIO Tagging
- Introduces 7 unique tags

Limitations
- dependency between classified tags
Hidden Markov Model (HMM)
- a generative model (models prob dist of the tokens) that assume states are generated from hidden states
- states follow a Markov chain
- states are not observed (no percepts)
- each state stochastically emits an observation
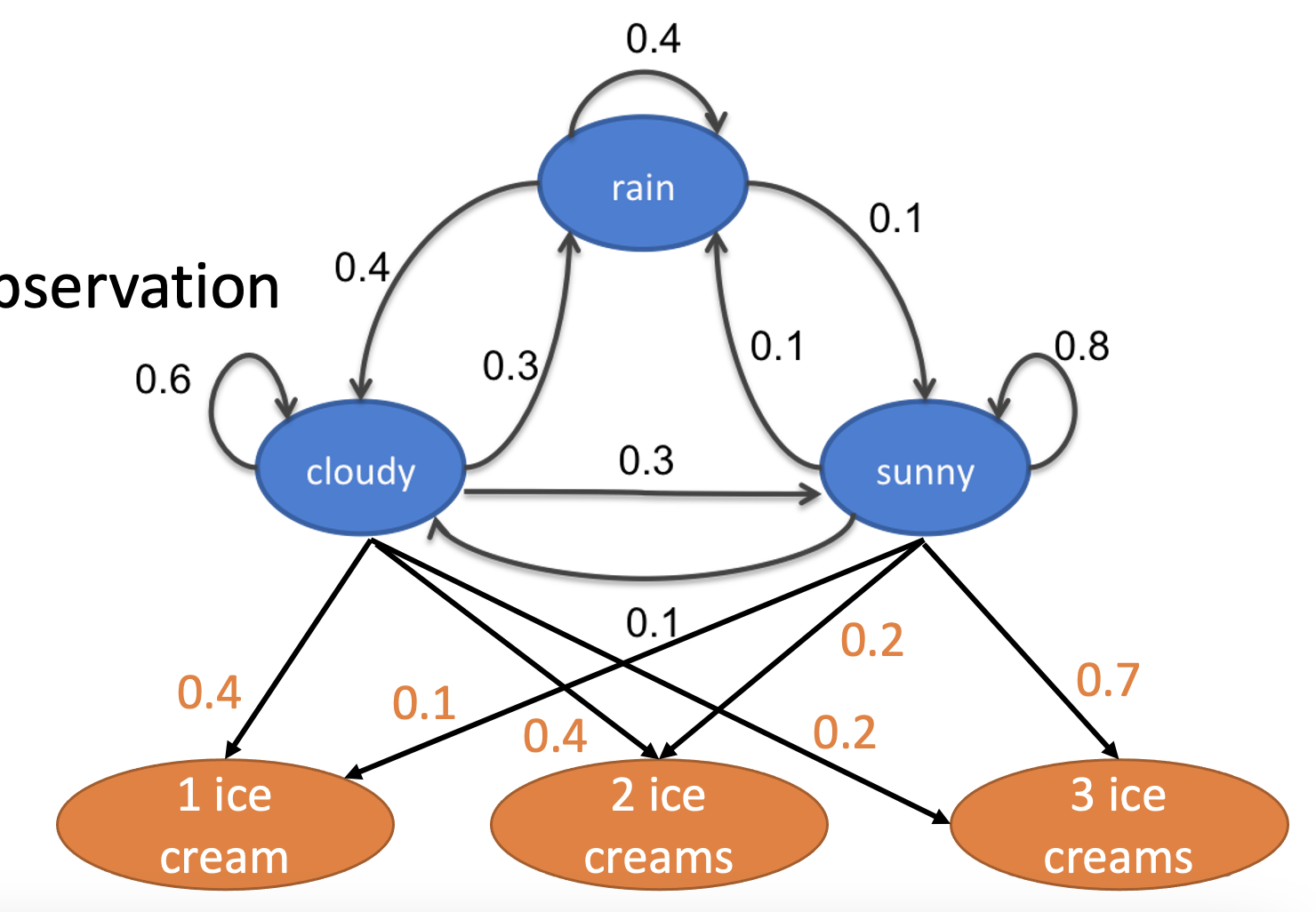
- e.g.,
Notation
- K is num of POS tags
- M is num of words

- to get the probability of the sequence (the above is joint):
Inference - find the most probable state seq (POS tag seq) given an input sentence: $$P(y_1,…,y_n x_1,…,x_n)=$$ - Learning - calculate
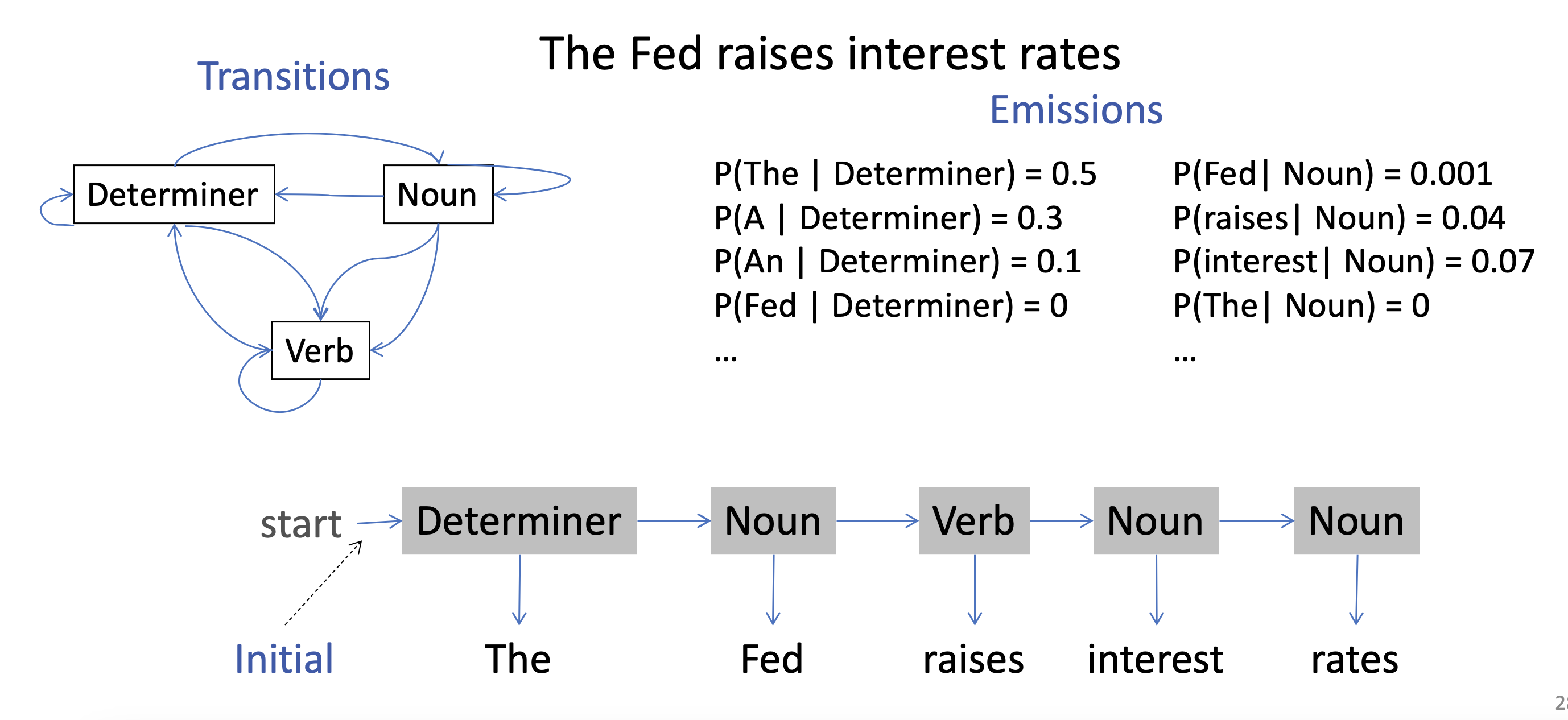
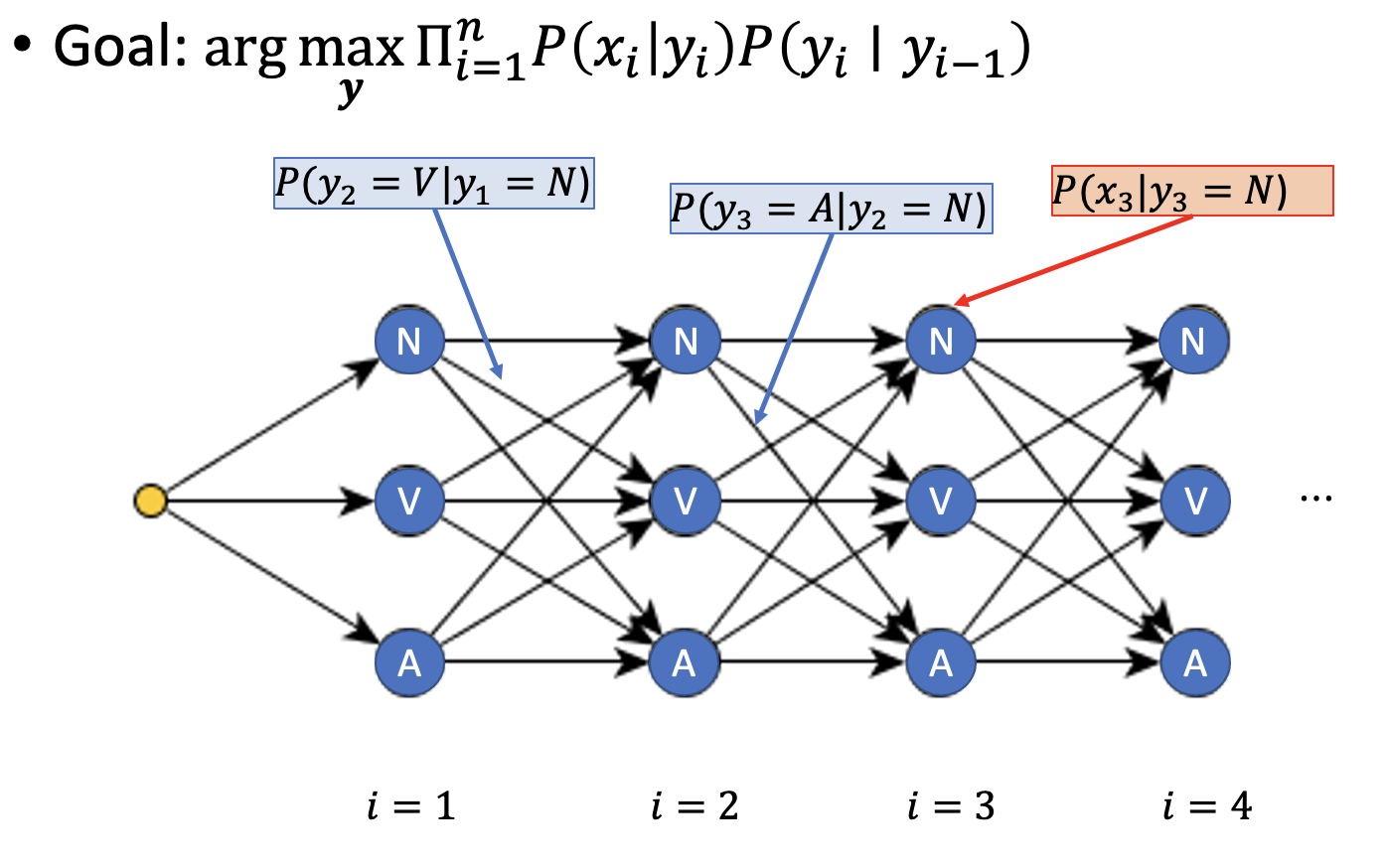
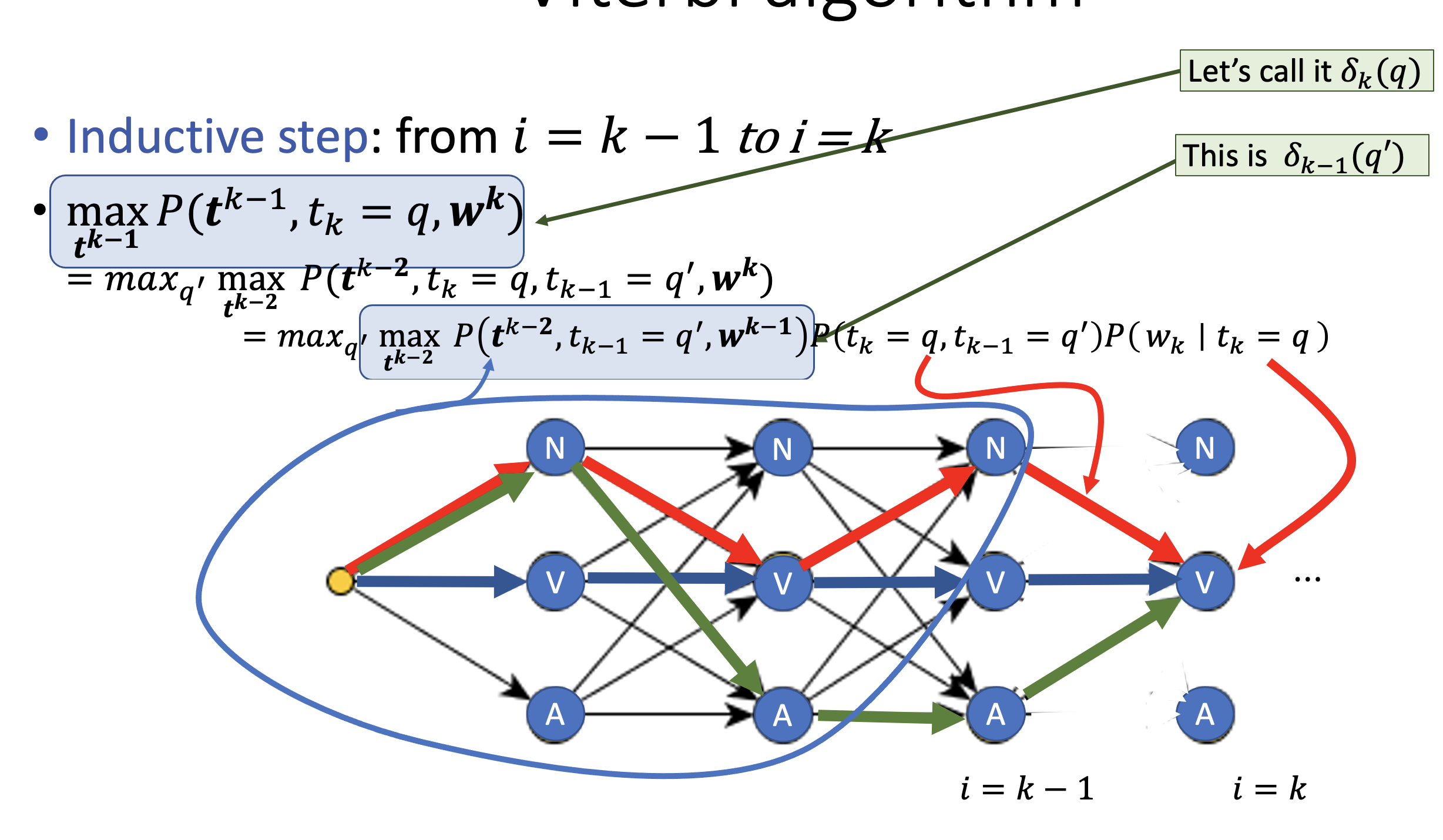
Inference: Trellis Diagram
- create a forward DAG where each edge has the transition probability and every node has the emission probability given the token at that layer
- In this image, the first layer is assumed “The” (most probable)
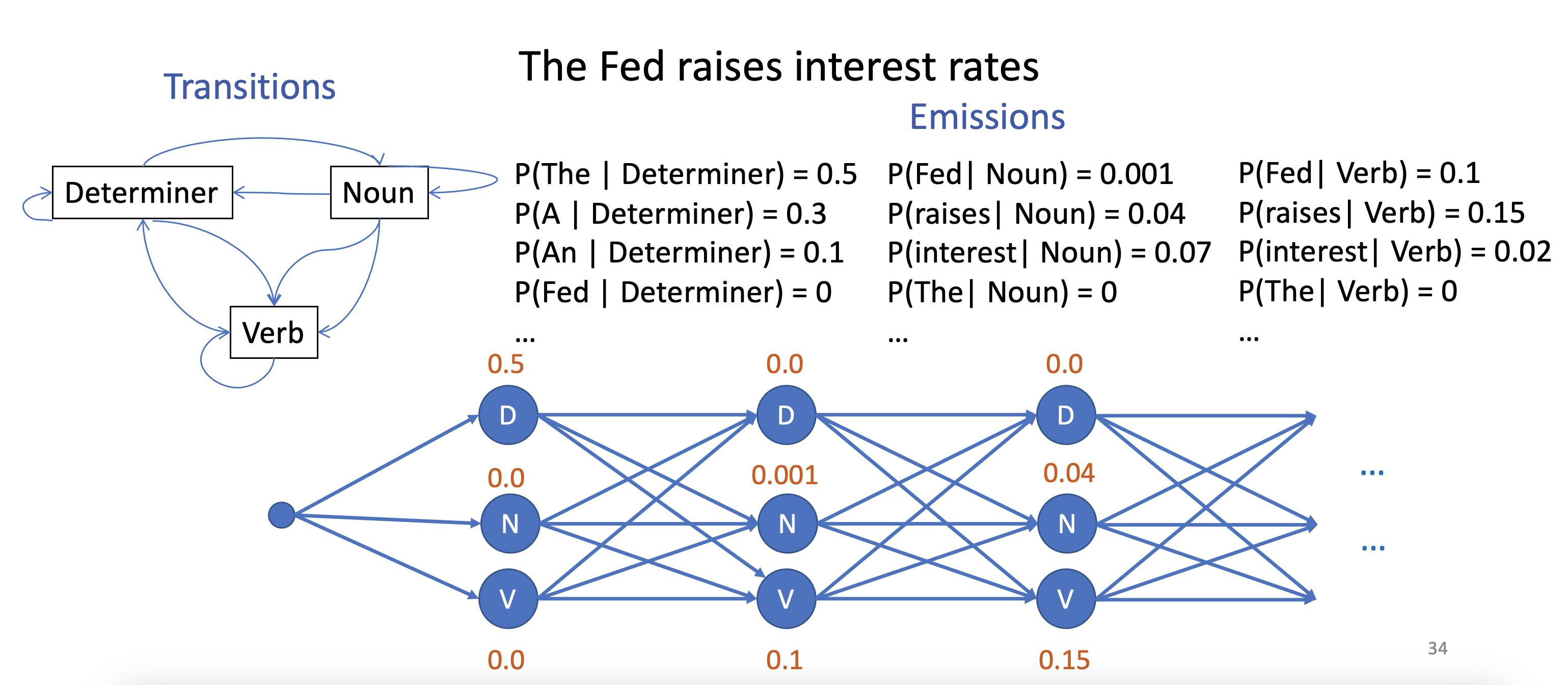
- thus we maximize over the sum of all possible tag sequence (maximum a posteriori)
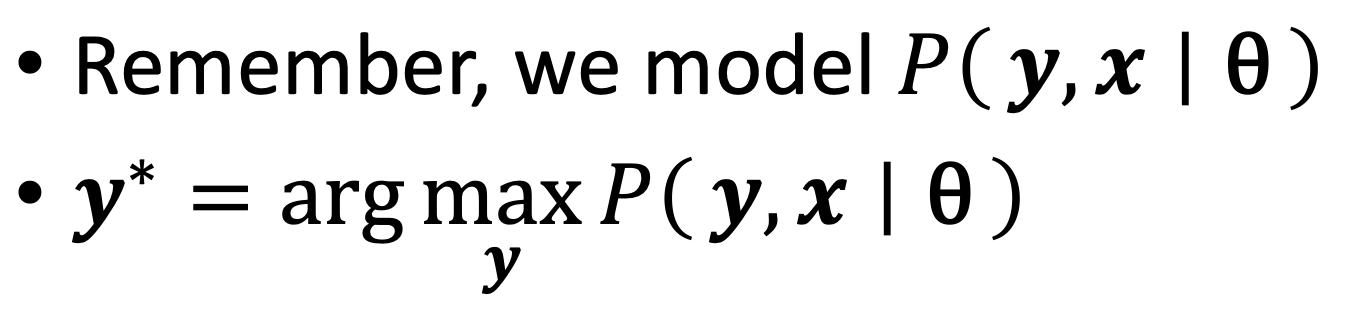
- e.g.,

- but this is too slow, so we need a faster algo (Viterbi)
Training
- can be done supervised (given
- learn HMM(
- do MLE on each of the training params of HMM (using count and divide)

Benefits/Limitations
- can do unsupervised training
- DP on Trellis
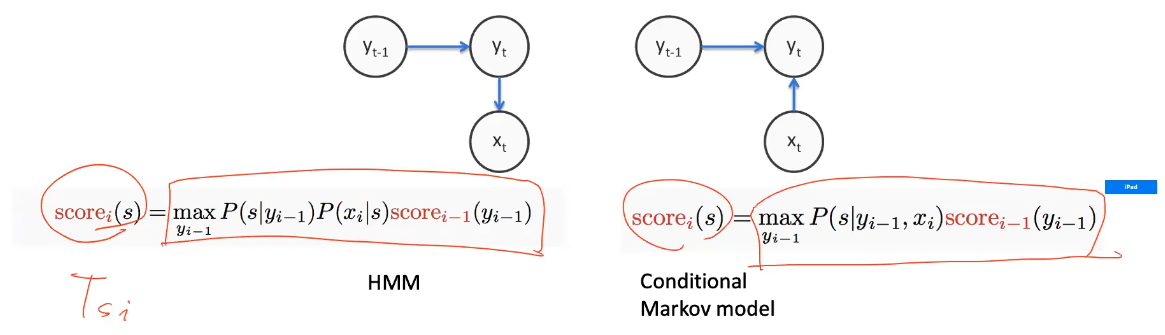
Recursive
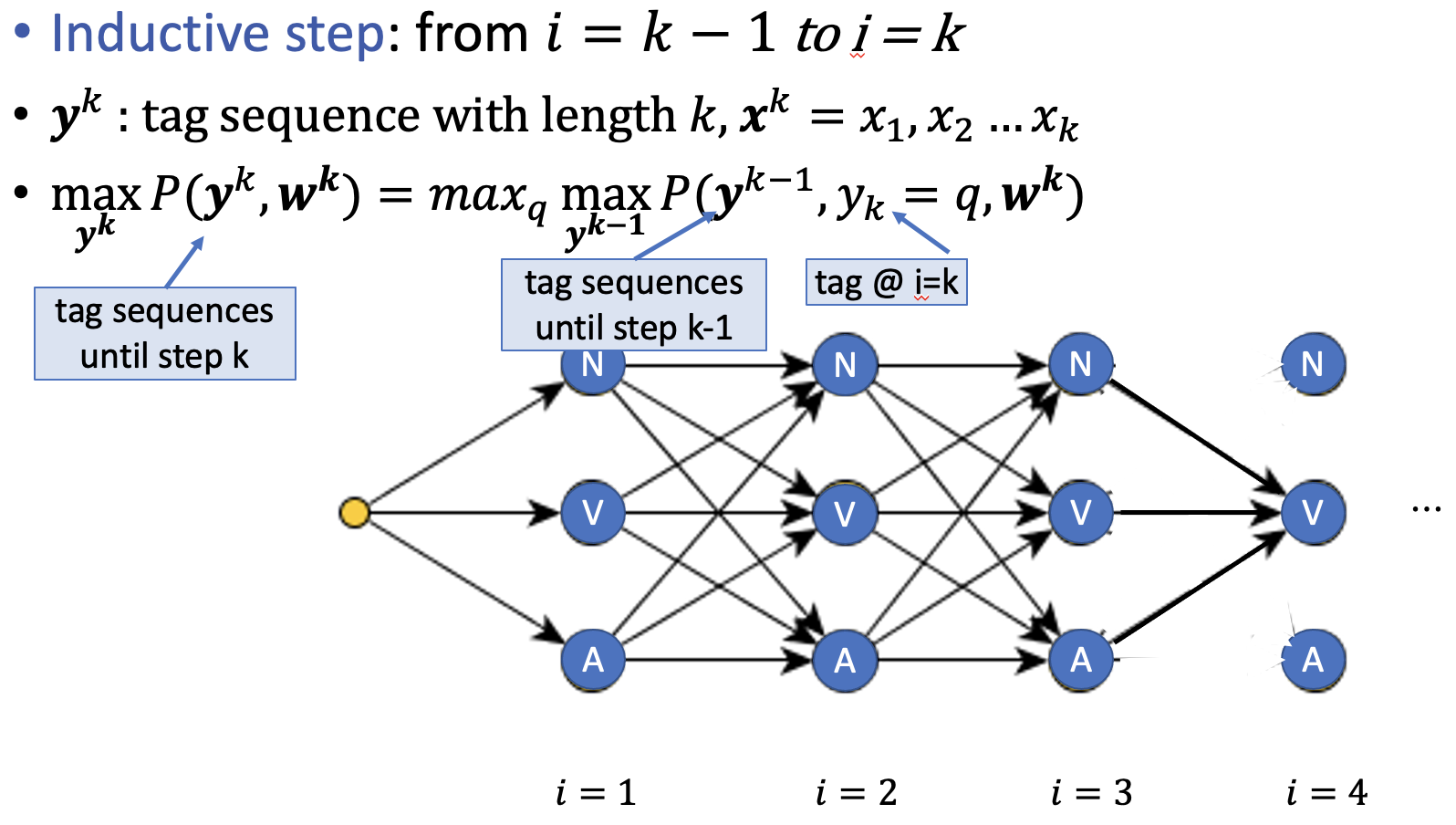
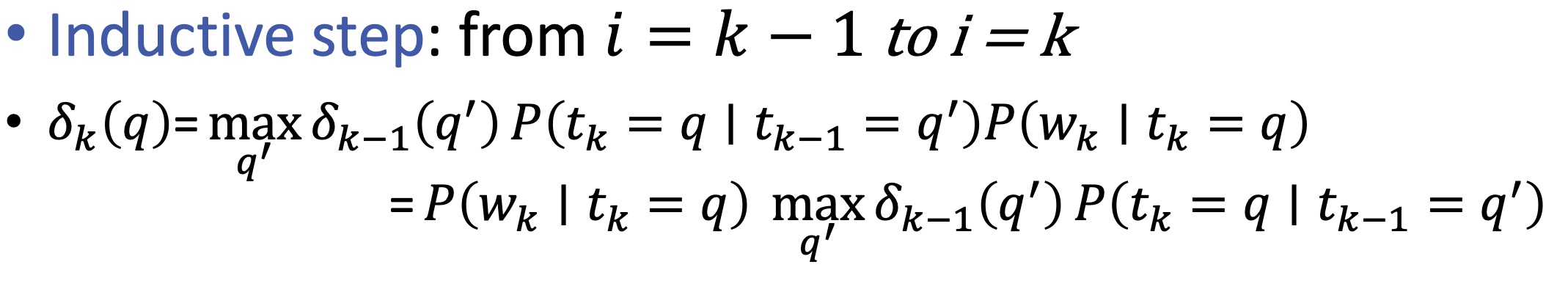
Tabular

Maximum Entropy Markov Models (MEMM)
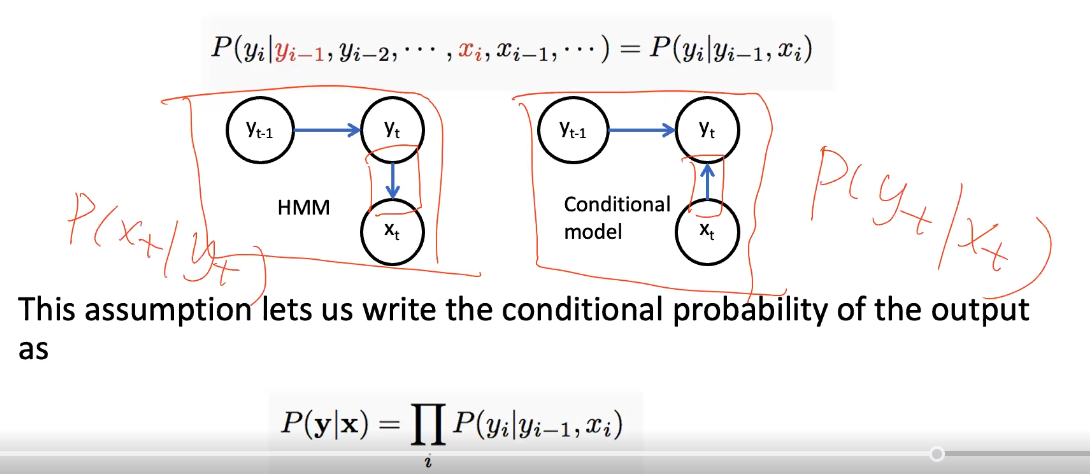
discriminative models $P(y x)$ - models the tag probs given the sequence/token
- MEMM is the conditional model, models “cliques” bc we can use Markov independence assumption
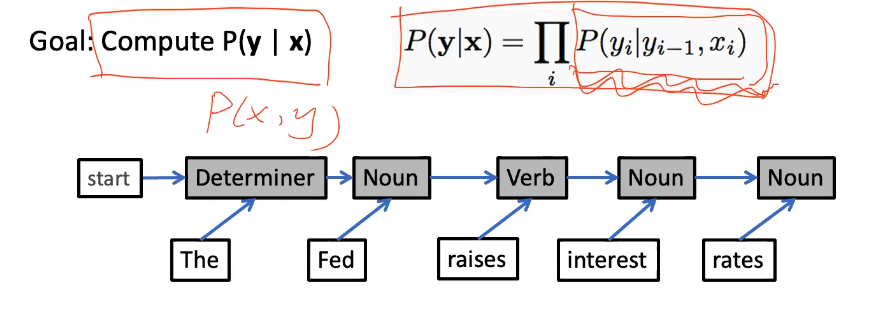
- thus we can use any cls, e.g. logistic regression model, perceptron:

- e.g.
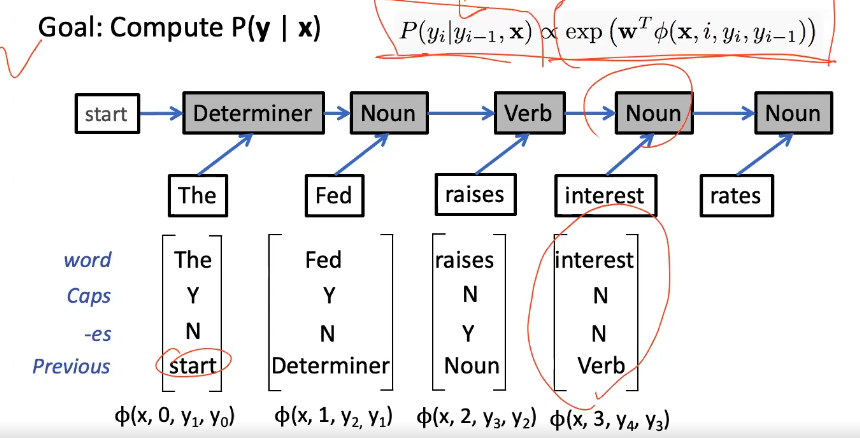
Training
- only supervised bc its a classifier
- same as any other log-linear model (or cls):

Inference
- Greedy (local) on trellis is still not optimal
- so we need “joint inference”: using DP
- thus, use the same Viterbi but with the different score
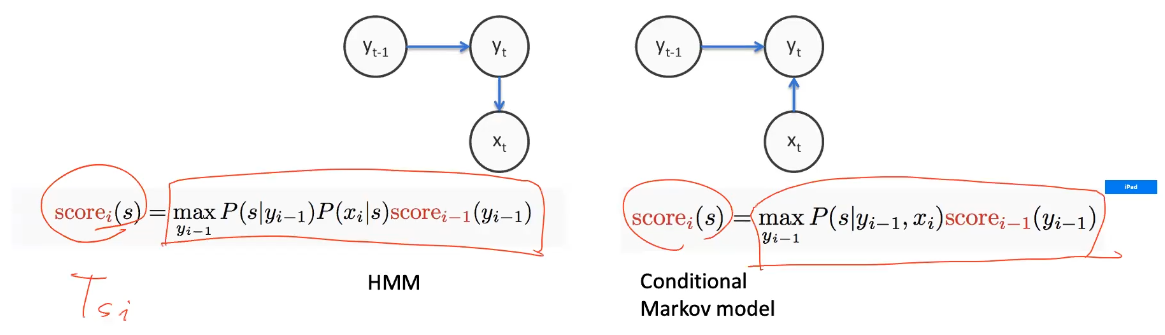
Benefits/Limitations
- rich feature representation of inputs using feature function/kernel
- discriminative predictor instead of joint
- no unsupervised training
- label bias problem
