9 - Transformers
ucla | CS 162 | 2024-02-09 02:15
Table of Contents
Seq2Seq Models
- input one sequence output another sequence
- e.g., audio -> text, text -> text (contextualized), text -> text
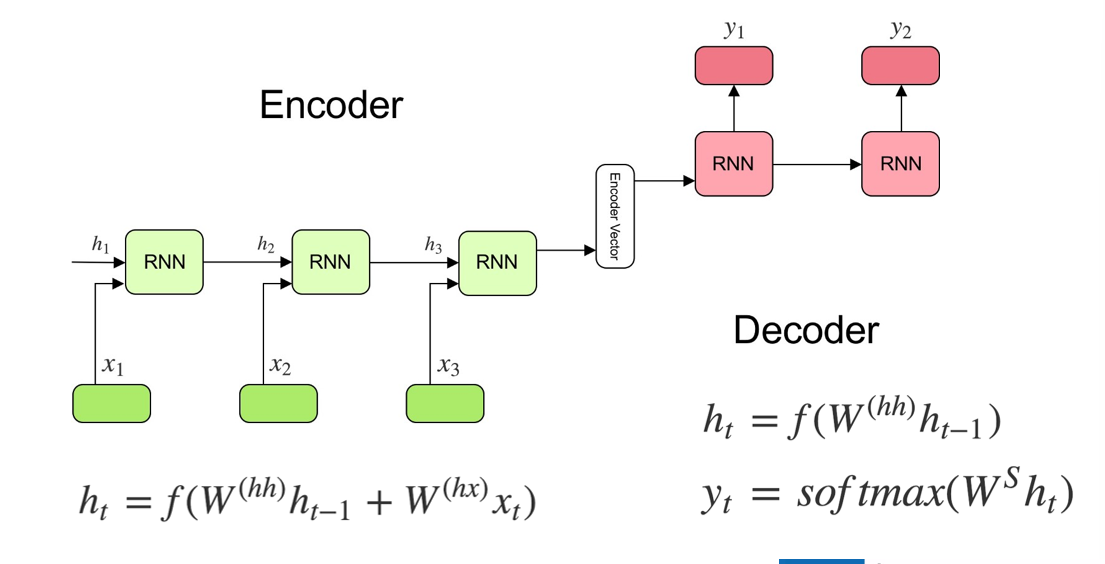
Encoder-Decoder Structure
- idea is to use output of last cell as encoded vector bc (w/ RNN at least) the last cell contains information and contxt on the entire sentence so far
Seq2Seq w/ Attention (Weighted sum)
- the pathway of encoder to context to attention vector; we compute attention by looking at all the attention vectors made by the encoder ($\overline{ h_s}$) and compare to the decoder cell attention ($h_t$) (see arrows from sep token in decode to attention weights from the encoder)
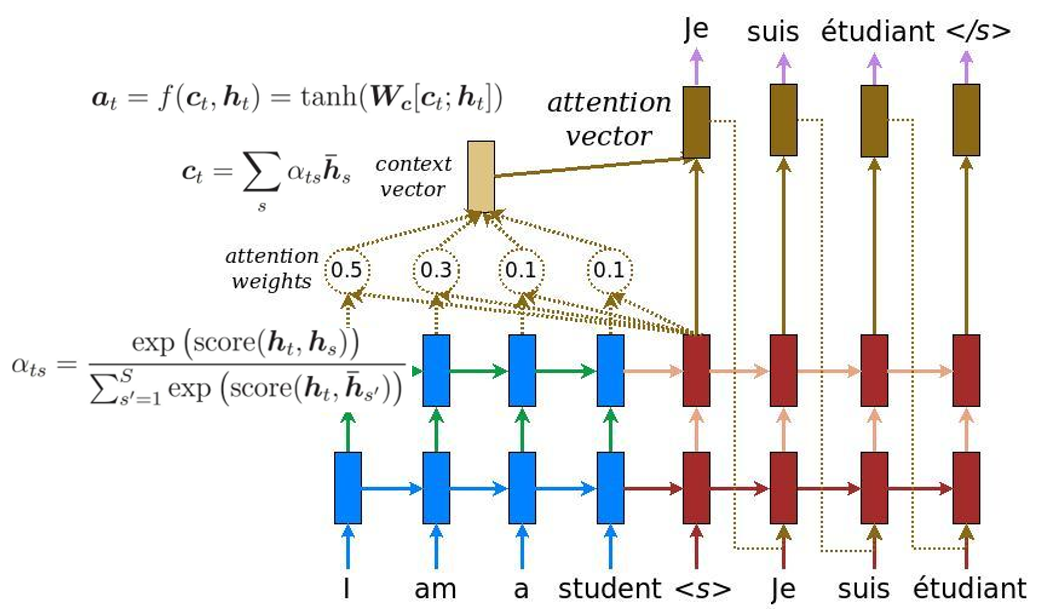
- we make predictions based on attention vectors instead of hidden states

Transformers
- relies entirely on attention for encoder-decoder model instead of relying on recurrent dependency -> parallelizable
Self-Attention
- attention between every token to every other token
- using QKV, compute the following circuits:
- QK circuit:
- Generate $\hat O=QK^T$ then norm & scale and softmax to get attentions \(Z=\text{attention}=O = \text{softmax}\bigg(\frac{QK^T}{\sqrt{d_k}}\bigg)\)
- OV circuit:
- generate contextualized (encoded) vectors by multiplying attention to each key/value s.t. \(C=OV=\text{softmax}\bigg(\frac{QK^T}{\sqrt{d_k}}\bigg)\cdot V\)
- we can parallelize and introduce new weights by first making the QKV matrices using weights and the inputs: \(Q=X\cdot W^Q\)\(K=X\cdot W^K\) \(V = X\cdot W^V\)
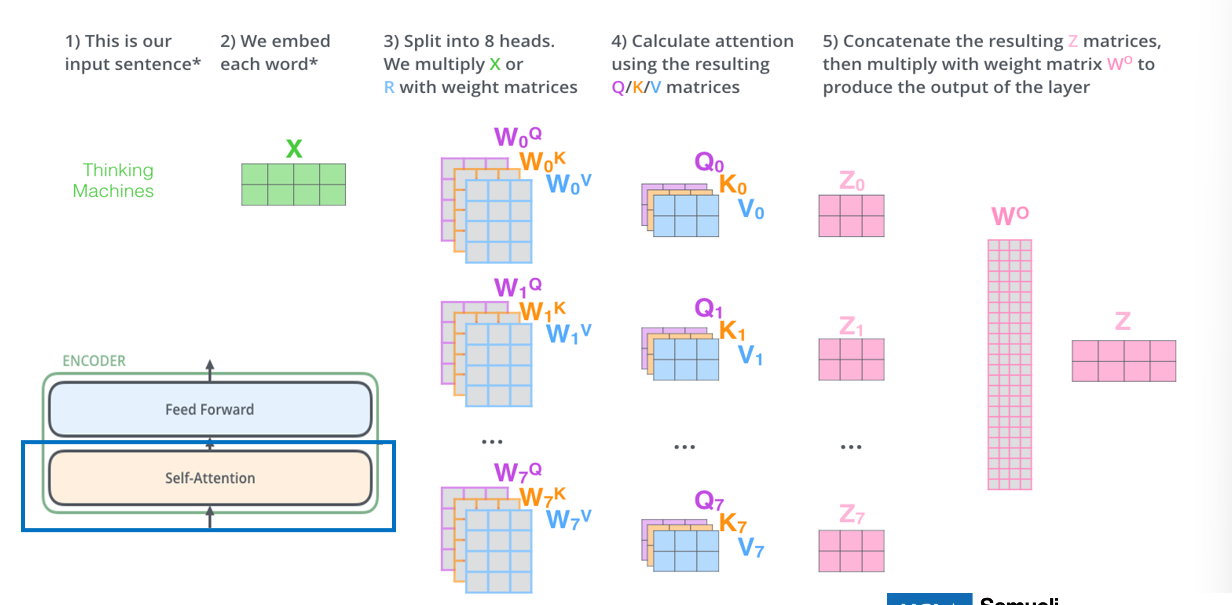
Multi-Headed Attention
- we create multiple self-attention heads using multiple QKV weight matrices and generate multiple contextualized versions of the input vector from each head:
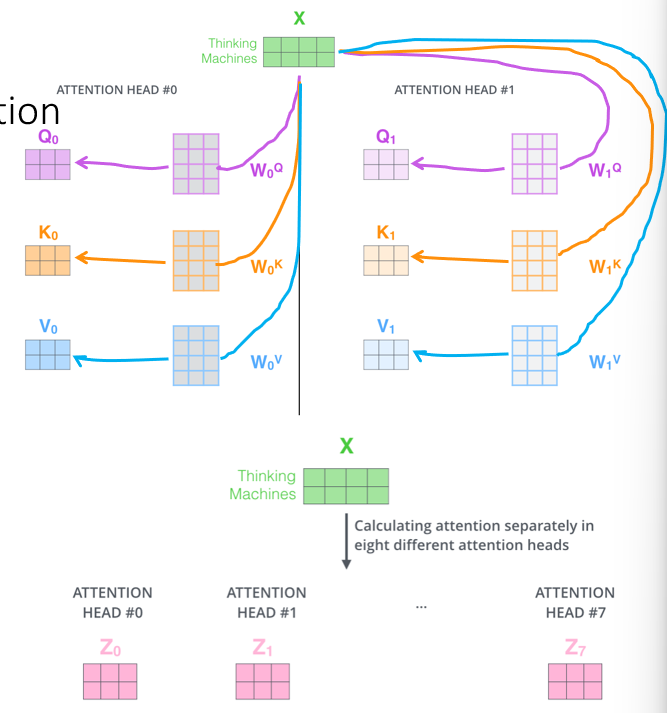
- then we concatenate the outputs and multiply by new output weight matrix $W^O$ and get a final contextualized matrix (by projection using the new weights) for the inputs:
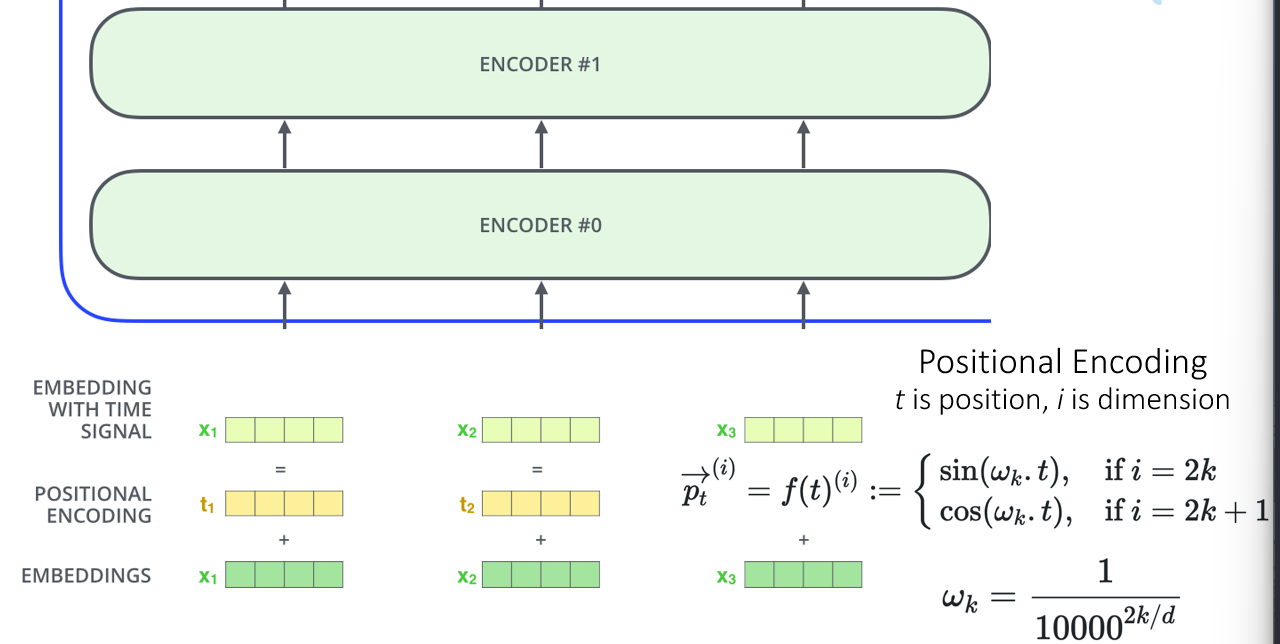
Positional Embedding
- something to be said abt positional relevance (words closer together likely are related in the same context), so we also include positional encoding along with input embeddings:
- t is the word position, k is the parity, i is the dimension index, d is the dimensionality
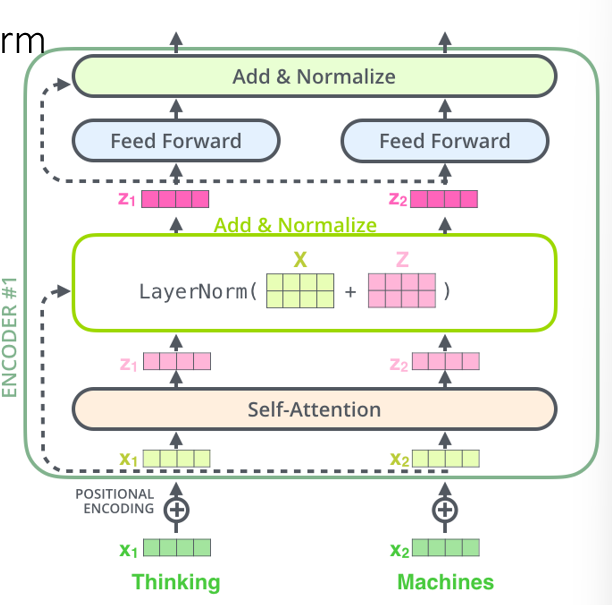
Residual Connections and Layer Norm
- information loss of the input vector multiple steps in + vanishing gradients -> add back in the sublayer through a residual connection:
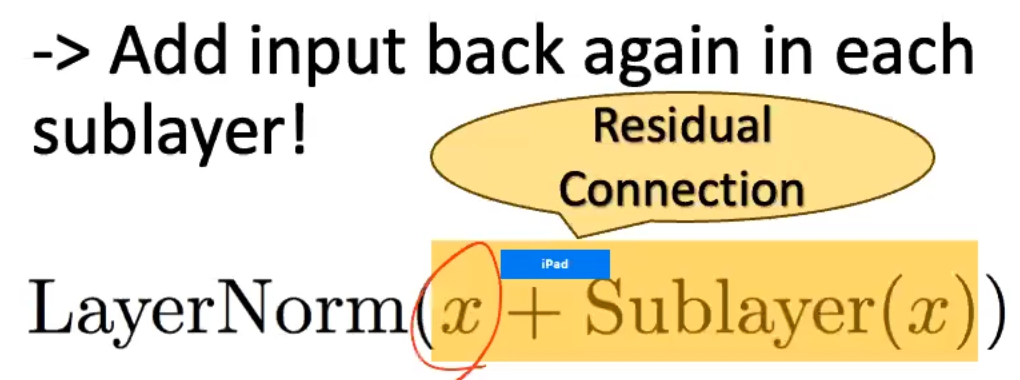
- and we want to normalize outputs by adding back in the original embeddings to the contextualized vectors
- for each dimension, normalize value wrt to mean to prevent vectors from becoming to large

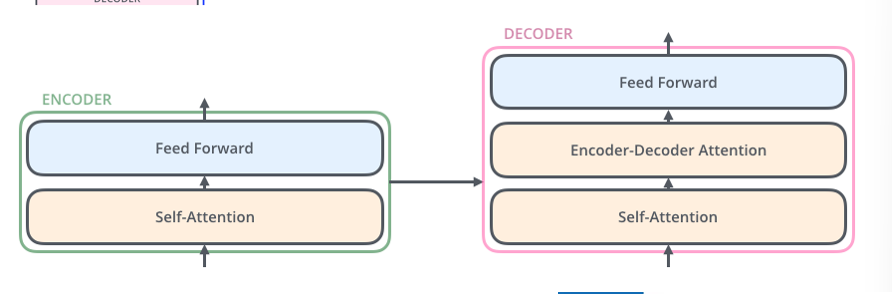
Encoder-Decoder Attention
- similar self attention but apply a look ahead mask after dimensional scaling in the self attention
- then pass that into Encoder-Decoder attention which is basically multi-headed attention but pass in Q,K as the contextualized representations from the Encoder