15 - Caches
ucla | CS M151B | 2024-02-29 16:17
Table of Contents
- Cache Sizing and Indexing
- Cache Replacement
- Write Policy
- Cache Misses/Performance
- Improving Cache Performance - Reducing Miss Penalty
- Reducing Hit Latency
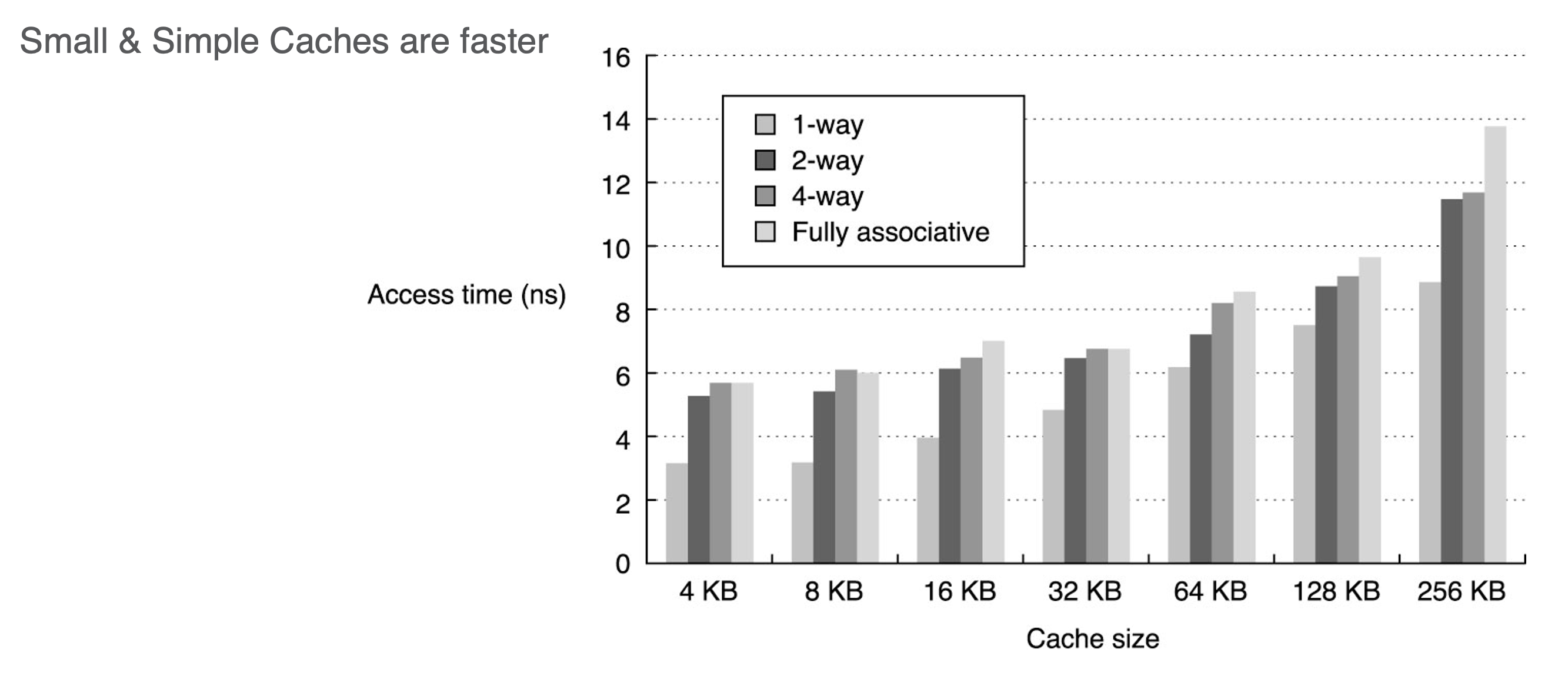
Cache Sizing and Indexing
- If we can afford 512 bytes of cache storage but our memory bus limit is 64 bytes
- we can store 512/64 = 8 blocks (cache lines)
- the cache adddress depends on addressibility (the examples are word addressable using 32 bit machine so cache addr = 32 bit - log2(4 byte word) = 30 bit addr) is then:
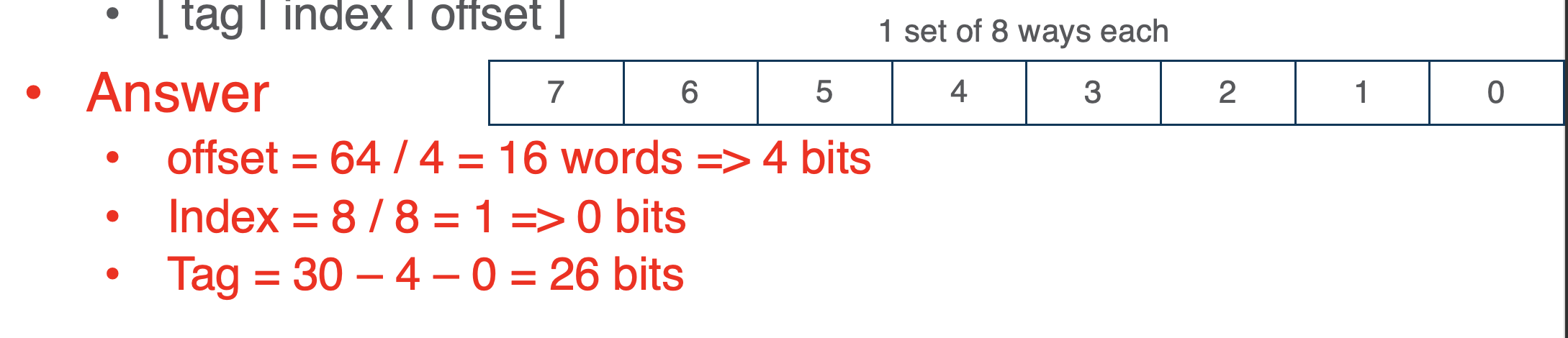
Direct Indexing
- if the cache lines are stored non-asociatively:
- offset = memory bus (64) / 4 = 16 (index through all addressable blocks in a single way - each way stores 16 bytes) =>
- index = 8 lines / 1 cache per line = 8 =>
- tag = 30 bit address - index - offset = 23 bits tag
- red are hits

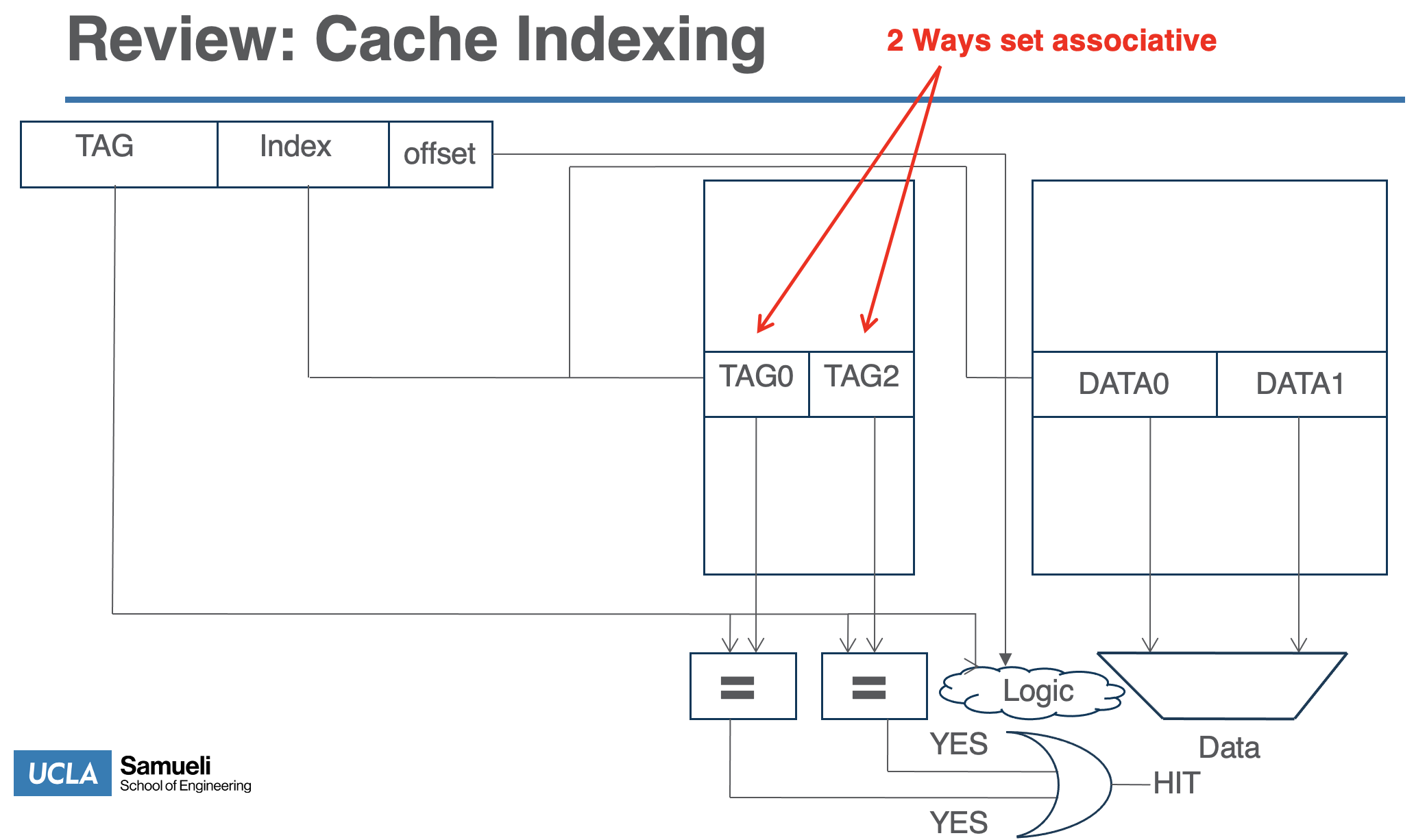
2-way set associative
- these have 2 cache lines per set so we can store 2 items at each index

- red are hits
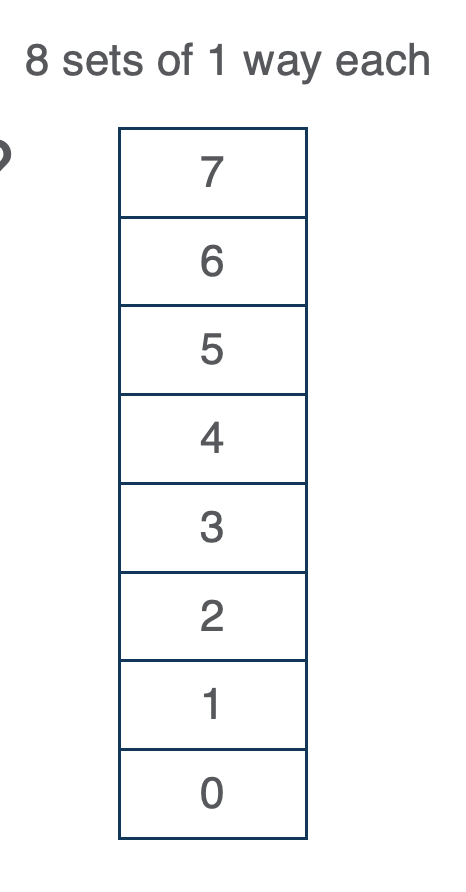
Fully associative
- no index bc everything is on the same index
Misses
- if the cache is full and misses
- we replace the least recently used at each index (set)
Structure
- the tag array and data array are both indexed by the ame index bits
- if the tag request matches the tag from the tag array in the caches, then it is a hit and we grab the data from the cache
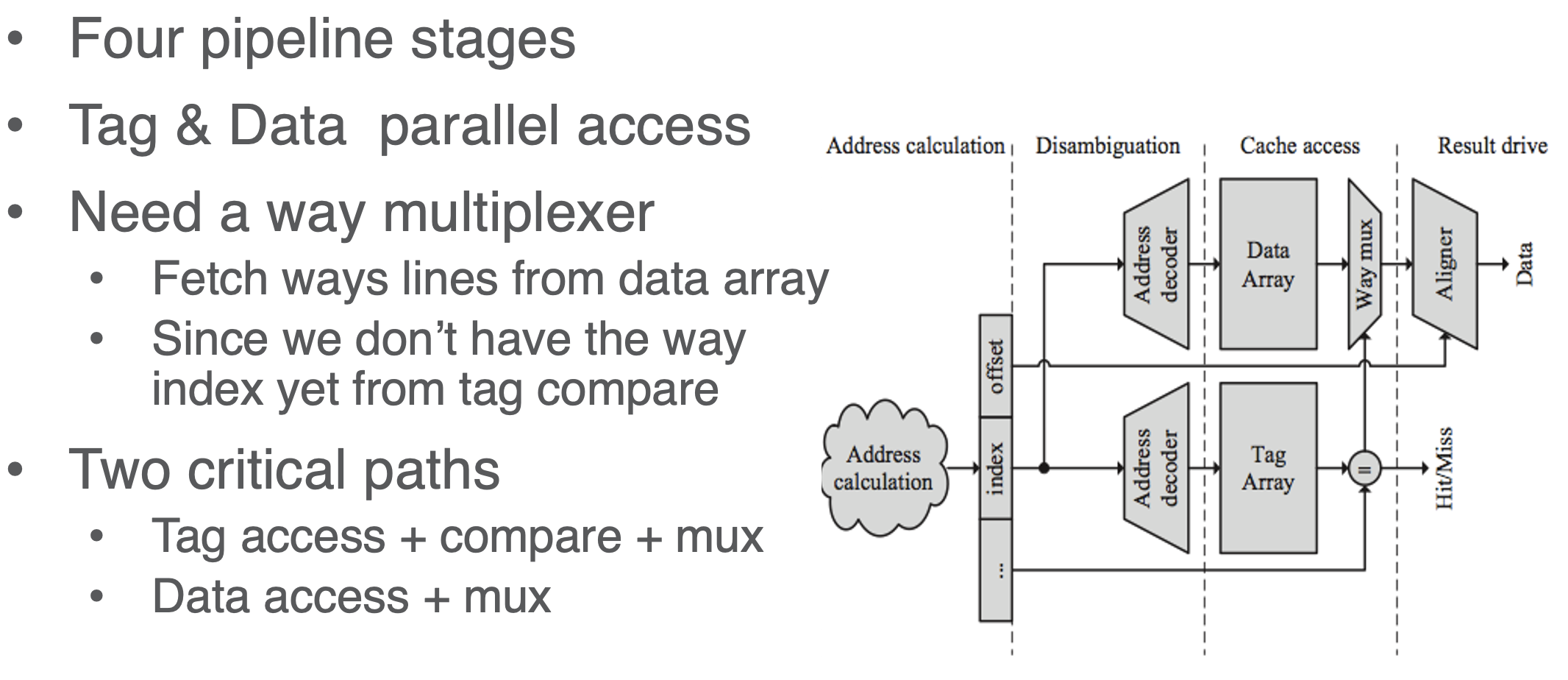
Parallel TAG and DATA access
- the issue is we have to first compare tags and find which tag to pull before accessing the data
- but bc this is done in parallel, the solution is to pull the entire data line
- e.g., if it is 4-way, we have to compare the TAG with T1,T2,T3,T4 but parallely we pull all of D1,D2,D3,D4 and THEN select from the MUX
- and here each Di in the data set is 64 bytes (the block size)
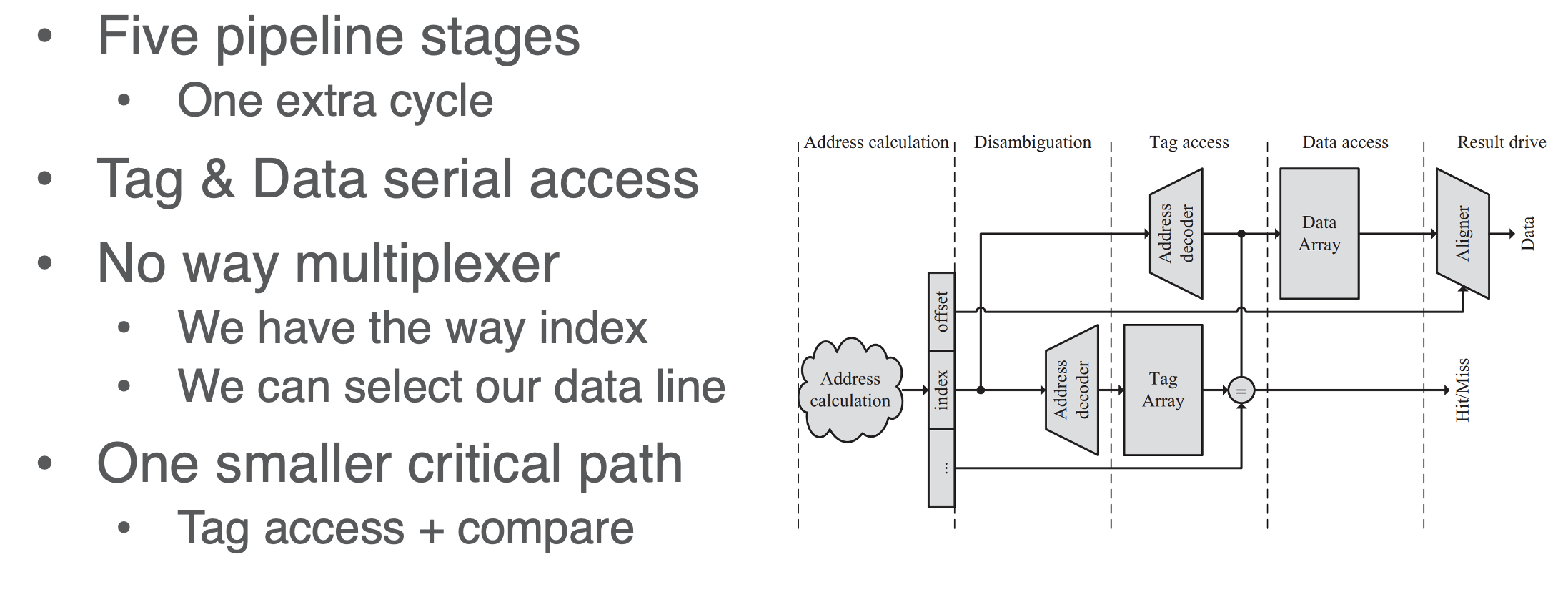
Serial TAG and DATA access
- to mitigate exces data indexing from parallel
- we compute the correct tag chck first, then push that to the DATA index to see which specific block from the indexed data line/set to select
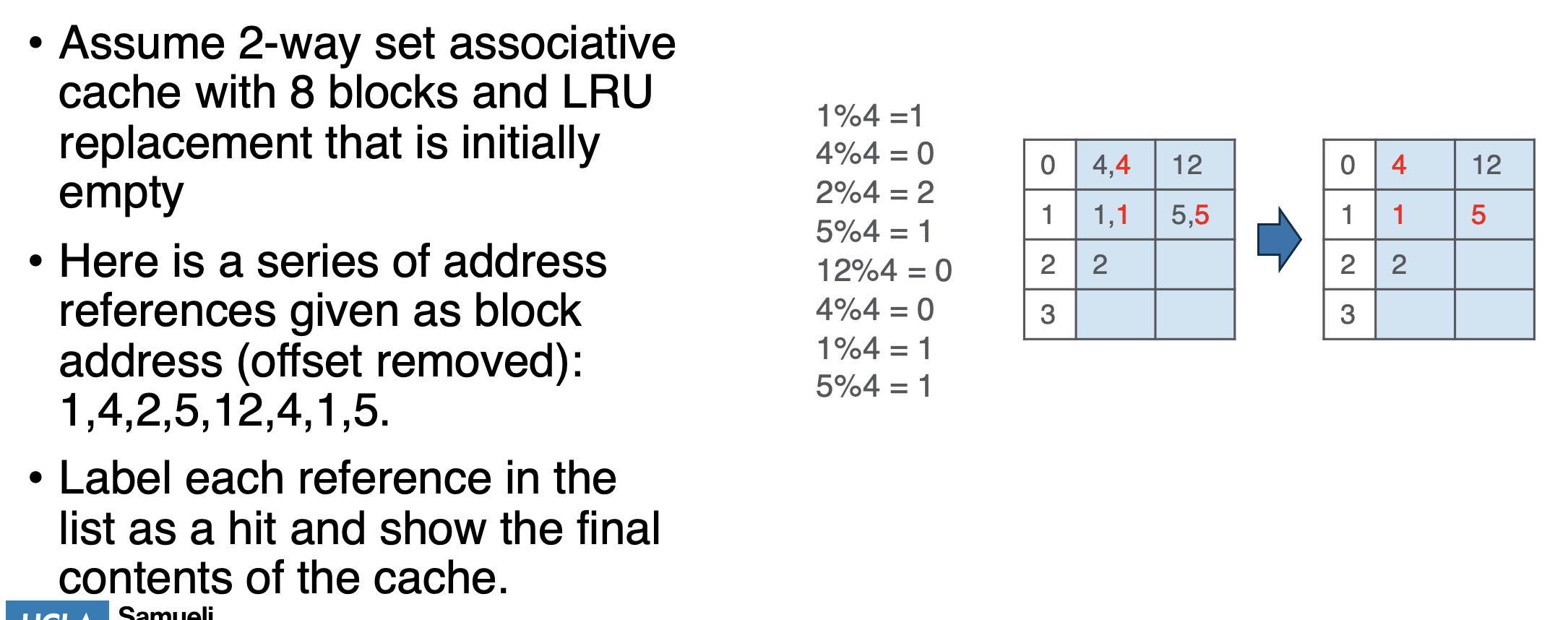
Cache Replacement
- random
- FIFO (line that has been in the cache the longest)
- LRU (least recently used line)
- LRU approx
Random
- use per set counter
- increment on set access
- on replacement, use counter val
- efficent but bad approx
LRU
- counter for each line (way i.e. every cache in every set at every index)
- when the line is accessed, reset its counter to MAX (= # of lines/ways per set - 1)
- decrement all other lines
- when replacement needed, select line with 0 counter (this should also be thee min)
- NOTE: there may be multiple 0 in this situation the tie breaker is an implementation detail - should be cheapest to access
- good approx, but expensive to calc
- e.g. 4 line cache

Tree-based Pseudo-LRU
- treat the cache lines of a set as teh leaves of a binary tree
- let the parents/ancestors be mapped to the bit positions, so 4-way set needs 3 bits for the tree - then 0 = take left, 1 = take right
- then idea is to trrack the most recently take branch (MRU) - which is jusst a 3-bit reg for each set - thus LRU = ~MRU
- e.g.

Write Policy
- question is should w allocate cache lines on a write miss (note we also save write addresses on the cache)?
- pro con depends on temporal locality of the program writes
- and after deciding this, should we update the write to just the cache or propagate to memory as well?
Write-allocate
- a write miss brings the block into cache
- bc we think we may use it later
Non-write-allocate
- write miss leaves cache as is
- just write to memory and don’t upddate bc we don’t think we’ll need the written block
Write-through
- write directly to memory on each write
- usually paired with non-write-allocate
Write-back
- memory updated only when line is replaced
- we write to the cache block
- usually combined with write-allocate
Dirty bit
- have a tag bit be the dirty bit
- starts out clean
- becomes dirty after first write back
- reset to clean after cache line is replaced
Cache Misses/Performance
Types of Misses
- Compulsory - required, e.g., when initialized everything is a miss
- Capacity - due to limited cache indices
- Conflict - due to limited associativity
Miss Rate
- fraction of misses of all memory access
- hit rate = 1 - miss rate
AMAT (Average Memory Access Time)
- AMAT = hit/access latency + miss rate * miss penalty/memory latency
CPU Perormance due to Cache Miss/Hit


Improving Cache Performance - Reducing Miss Penalty
Better MLP
- to reduce AMAT latency, we can employ better Memory Level Parallelism (MLP)
- e.g.

Overlapping misses: Hiding miss latency
- a blocking cache - allow only 1 cache access at a time
- if it is a miss, it stalls until the access get teh true hit
- non blocking - opposite of blocking cache
- hit under miss - while the first access misses, the second can hit in the meantime
- miss under miss - if second also misses, we have to stall
- we need MSHR (miss status holding register) - stores missed cache requests waiting for memory access
- tracks addres, data, and status for outstanding misses
- has a max capacity so need to check for full
- can be shared by multiple caches
- prefetching - predict which cache will be called, if this is a miss we can run next prefetching in the meantime
Multi-level caches
- The L1 miss penalty is determined by AMAT of L2 and so on:

Inclusion or Exclusion Policy
- firmware should decide if cahces will be:
- inclusive - if a block is in L1 it is also in L2 and every level down
- easier file management and eviction
- exclusive - if a block is in L1 it will not be in L2 or any other level down
- if the Bus becomes the bottleneck (bc it is too narrow) during block transfer (serving a miss by moving memory to cache lines), we can handle in 2 ways
- Early restart - begin loading block word by word -> when a word is needed -> let CPU use -> then continue block transfer to fill cache line
- Critical Word First - transfer necessary word first to cache line -> then load in the rest of the block
- loads can have dependent operations so if a load misses, let it go before stores
- so we need a write buffer to track outstanding stores
Optimizing write buffer
- each time a load misses we load a block (e.g. 64 bytes) just for a 4 Byte word
- intstead, we can use the prioritizing memory transactions to mack loading faster, but we do this before handling stores
- so for stores that are outstanding we can store them together in the write buffer so we only write to memory a full block
- this means we also should check the write buffer first if we need to load a block and it misses
Victim caches
- keep recently evicted blocks in a much smaller cache (victim cache)
- so if we miss on them, we can still get them fast - mitigates conflict misses
- e.g.

Larger Blocks
- there are drawbacks
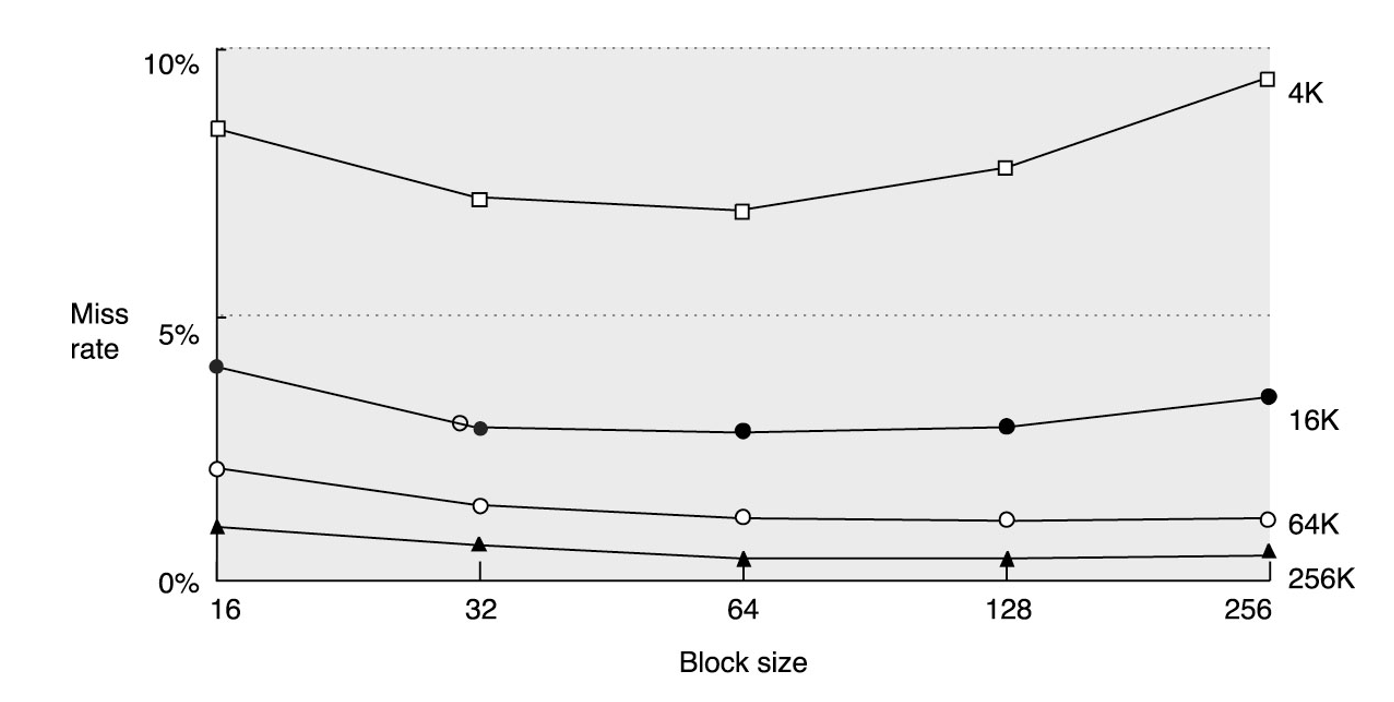
- larger caches - fewer capacity misses, but longer hit latency
- more associativity - fewer conflict misses, longer hit latency
- decide based on AMAT
Pseudo-associative caches
- treat caches as direct indexed (Associative but we have a primary cache line in the set)
- if we miss on the primary line, then check secondary
- use a hash function to determine which indices to check or to check secondaries
Compiler/Software optimization
Loop interchange
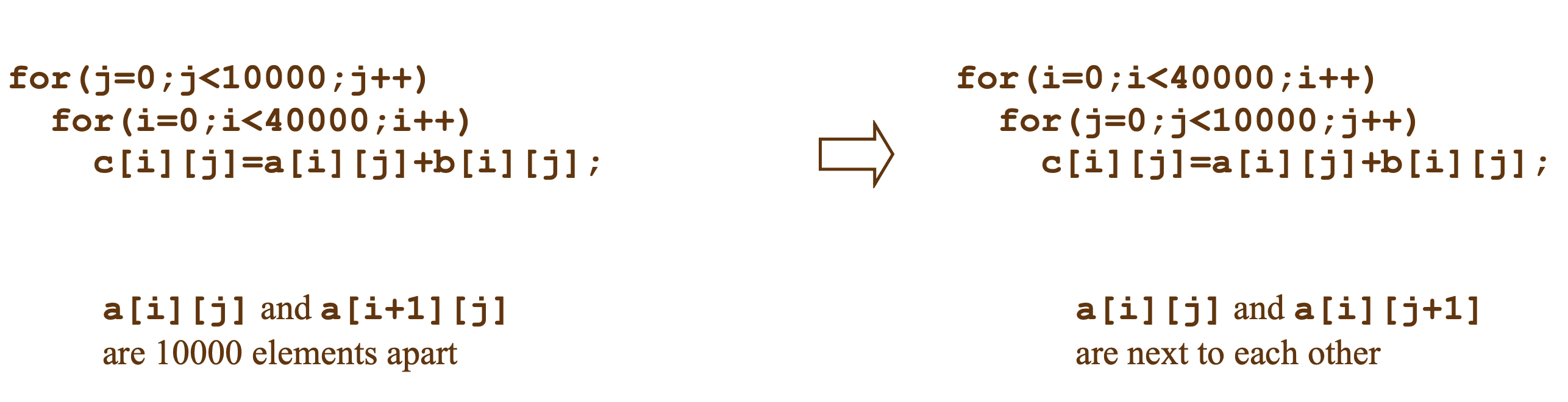
Blocking
- e.g., tiling MATMUL

Data alignment
- using aligned malloc/alloc - increase spatial locality
Hint bits
- increase temporal locality
Reducing Hit Latency